SecStrAnnotator:Analysis: Difference between revisions
| Line 12: | Line 12: | ||
* annotation, | * annotation, | ||
* multiple sequence alignment for individual SSEs, | * multiple sequence alignment for individual SSEs, | ||
* formatting into SecStrAPI format, | * formatting into [[SecStrAnnotator:SecStrAPI#SecStrAPI_format | SecStrAPI format]], | ||
* formatting into TSV format for further analyses. | * formatting into TSV format for further analyses. | ||
Revision as of 15:15, 9 April 2020
SecStrAnnotator Suite provides scripts (Python, R, and bash) for batch annotation of the whole family and analysis of the annotation results.
Procedure
Data preparation
The directory scripts/secstrapi_data_preparation/ contains a pipeline for annotating the whole protein family, including:
- downloading the list of family members defined by CATH and Pfam,
- downloading their structures,
- selecting a non-redundant set,
- annotation,
- multiple sequence alignment for individual SSEs,
- formatting into SecStrAPI format,
- formatting into TSV format for further analyses.
Example usage:
bash scripts/secstrapi_data_preparation/SecStrAPI_master.sh
Before running, modify the SETTINGS section of SecStrAPI_master.sh to set your family of interest, data directory, options, paths to your template annotation (TEMPLATE_ANNOTATION_FILE, TEMPLATE_STRUCTURE_FILE). Unwanted steps of the pipeline can be commented out in the MAIN PIPELINE section.
Data analysis
The directory scripts/R_sec_str_anatomy_analysis/ contains a pipeline for statistical analysis of the annotation results on the whole protein family, including:
- reading the annotation results from TSV,
- generating plots,
- performing statistical test to compare eukaryotic and bacterial structures (or any two sets of structures).
Example usage:
- Launch
rstudiofrom the said directory - In
sec_str_anatomy.R, set DATADIR to the path to your annotation data created in #Data preparation - In
sec_str_anatomy_settings.R, modify the family-specific settings (list of helices and strands) - Run
sec_str_anatomy.Rline by line
Example case study: Cytochromes P450
Data
For the Cytochrome P450 family, structures of 1775 protein domains are available, located in 953 PDB entries. The analysis was performed on a non-redundant subset containing 175 protein domains.
The data are available here (structural files not included because of their size).
Occurrence of SSEs
The occurrence describes in what percentage of the structures a particular SSE is present.
-
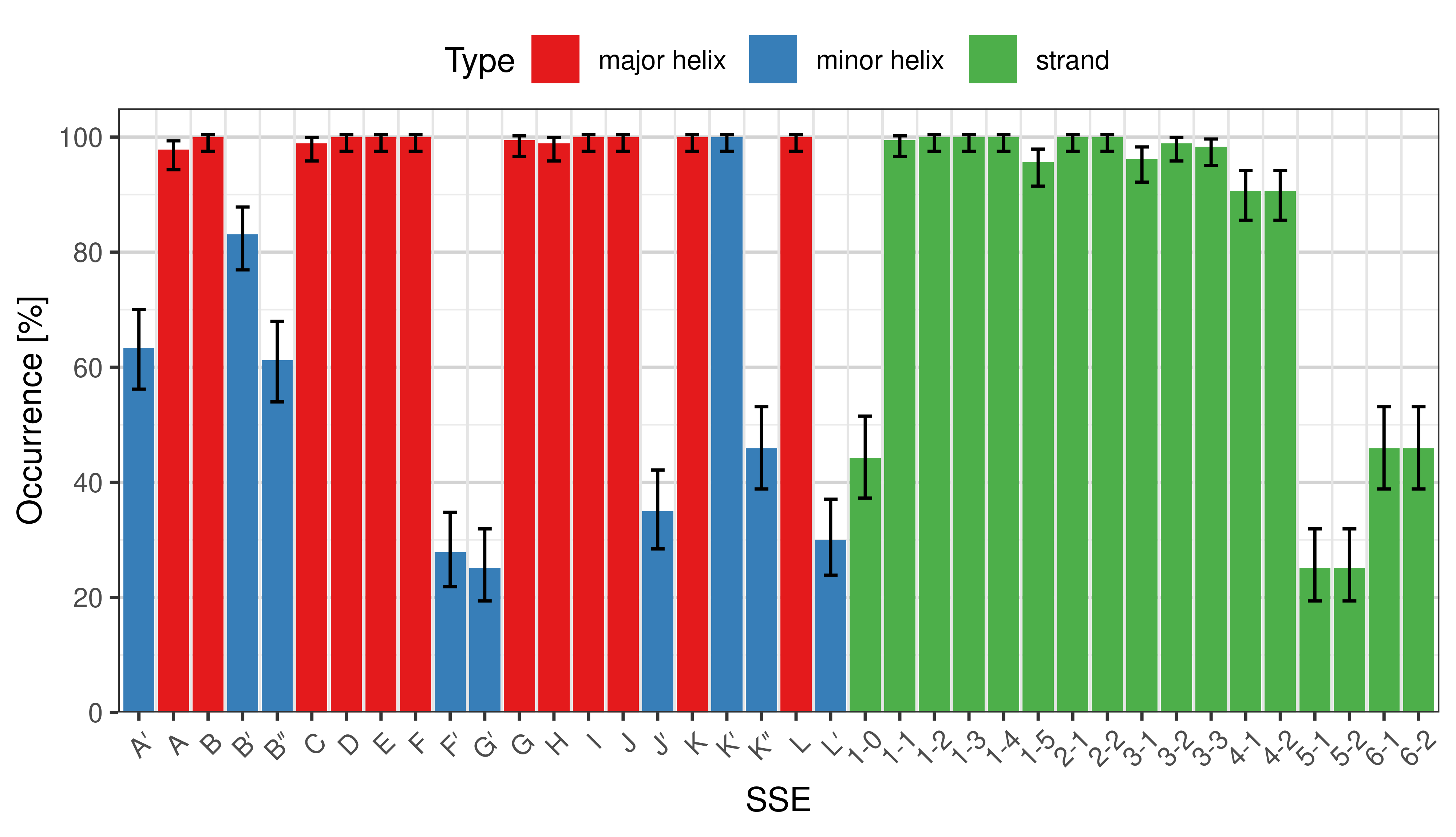
Occurrence of particular SSEs in the whole set. -
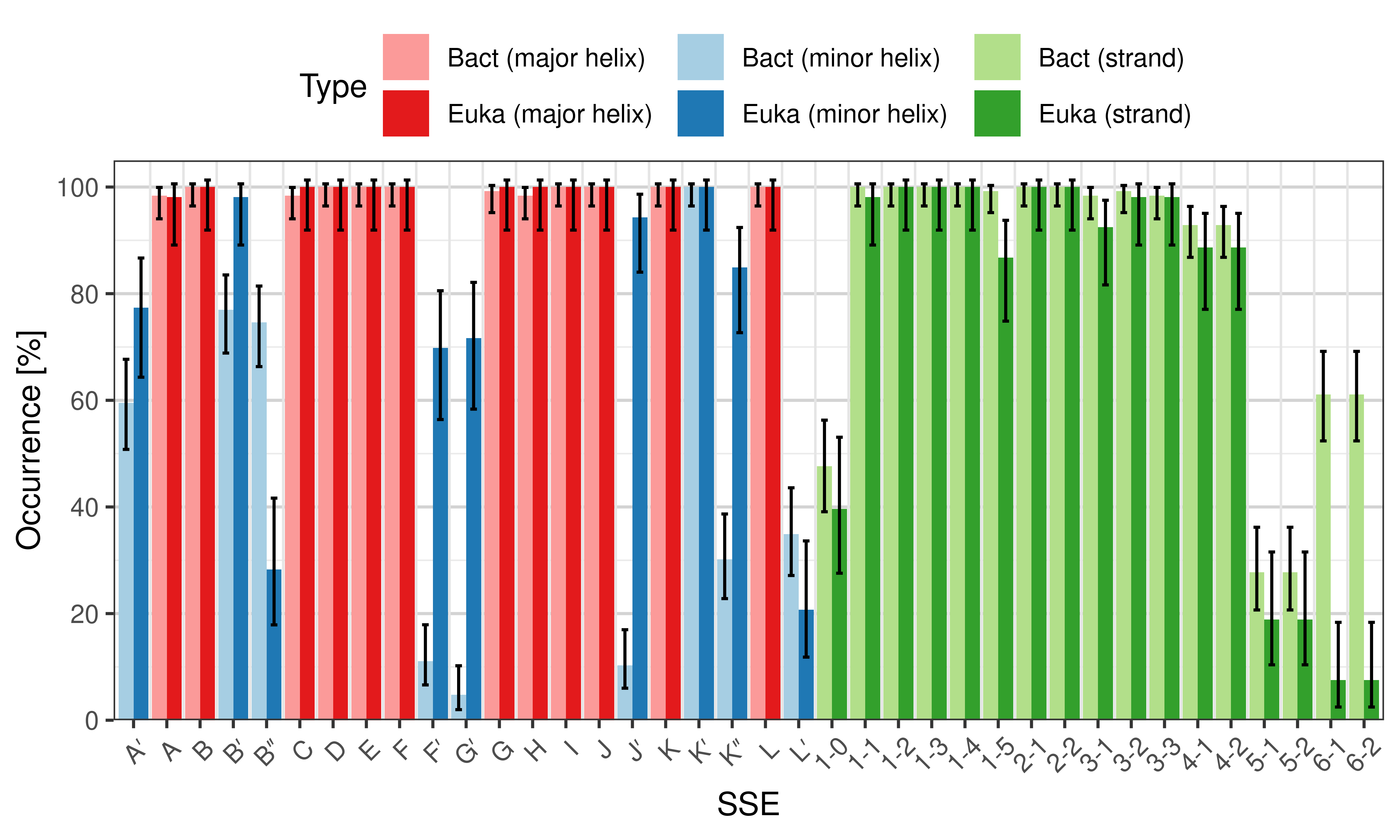
Occurrence of particular SSEs – comparison of bacterial and eukaryotic structures.


Length of SSEs
The length of an SSE is measured as the number of residues. The following violin plots show the distribution of length for each SSE.
-
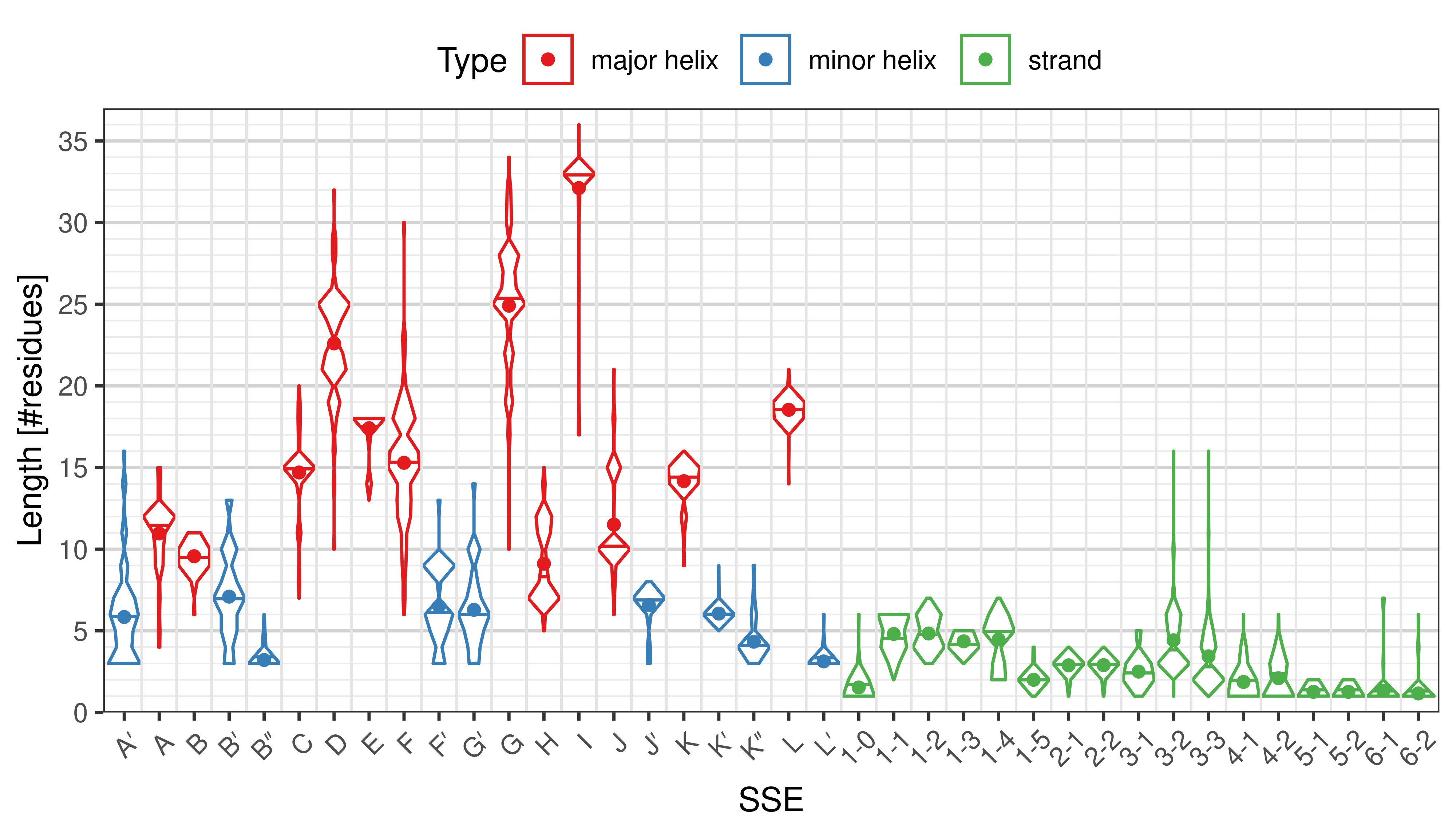
Length distribution of particular SSEs in the whole set. -
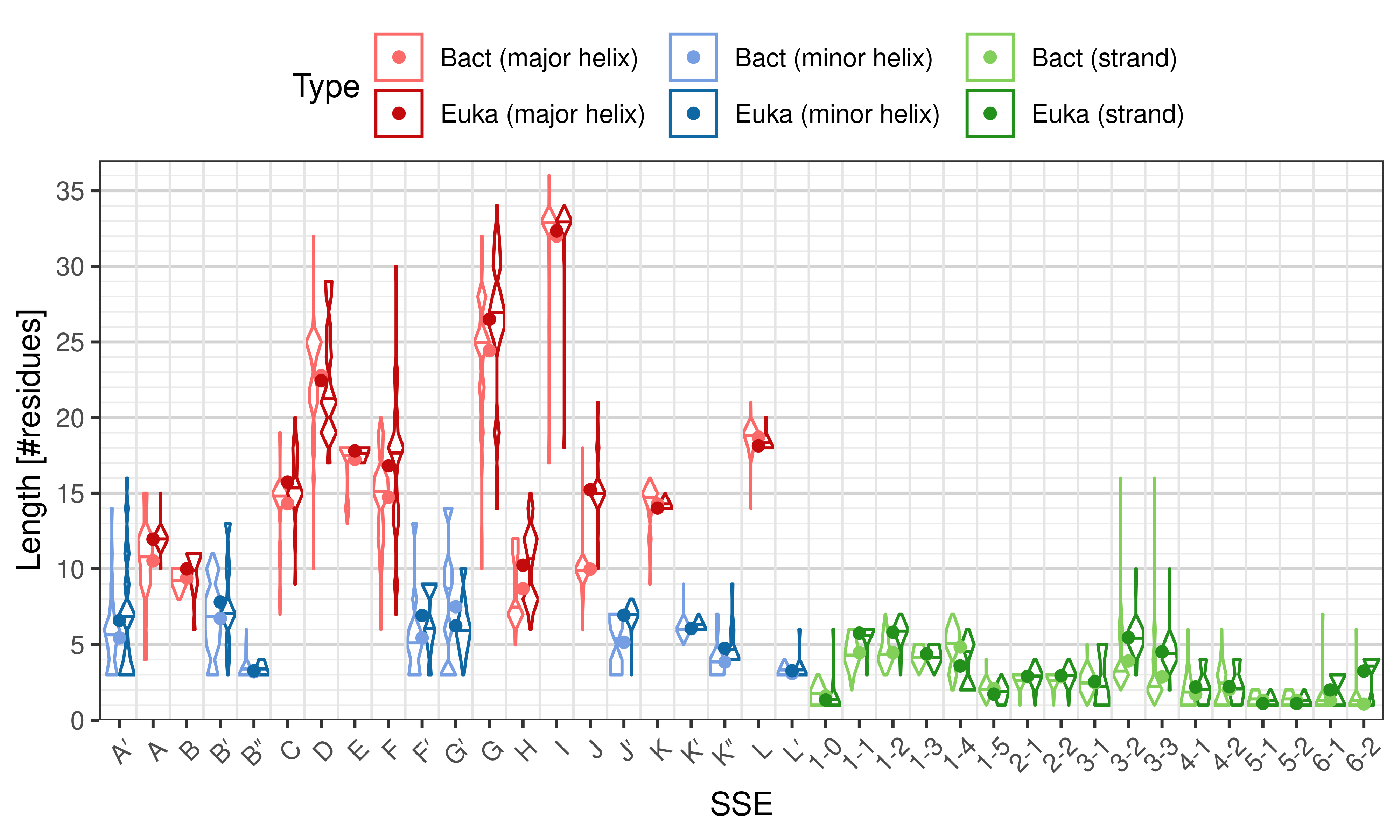
Length distribution of particular SSEs – comparison of bacterial and eukaryotic structures.


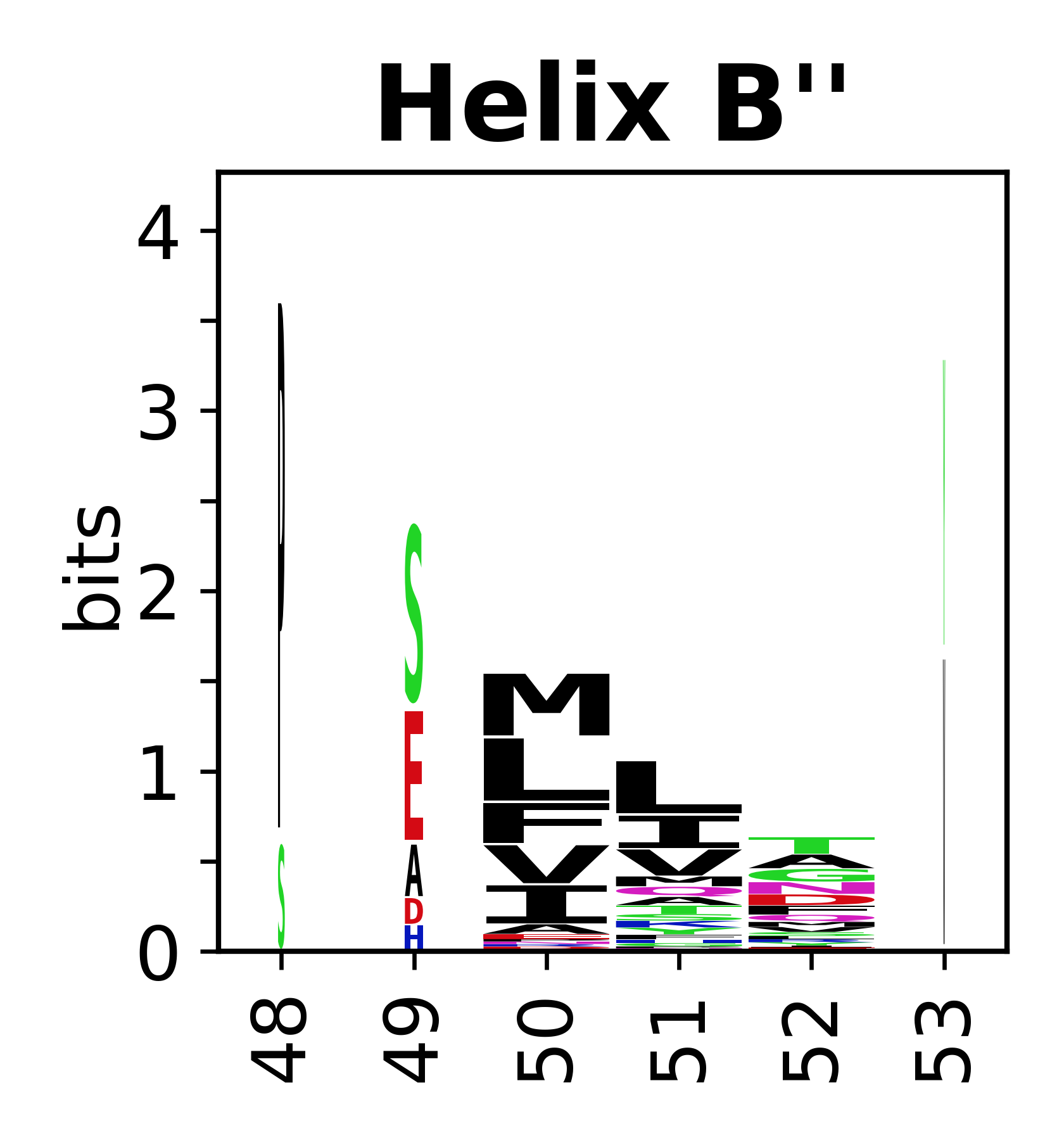
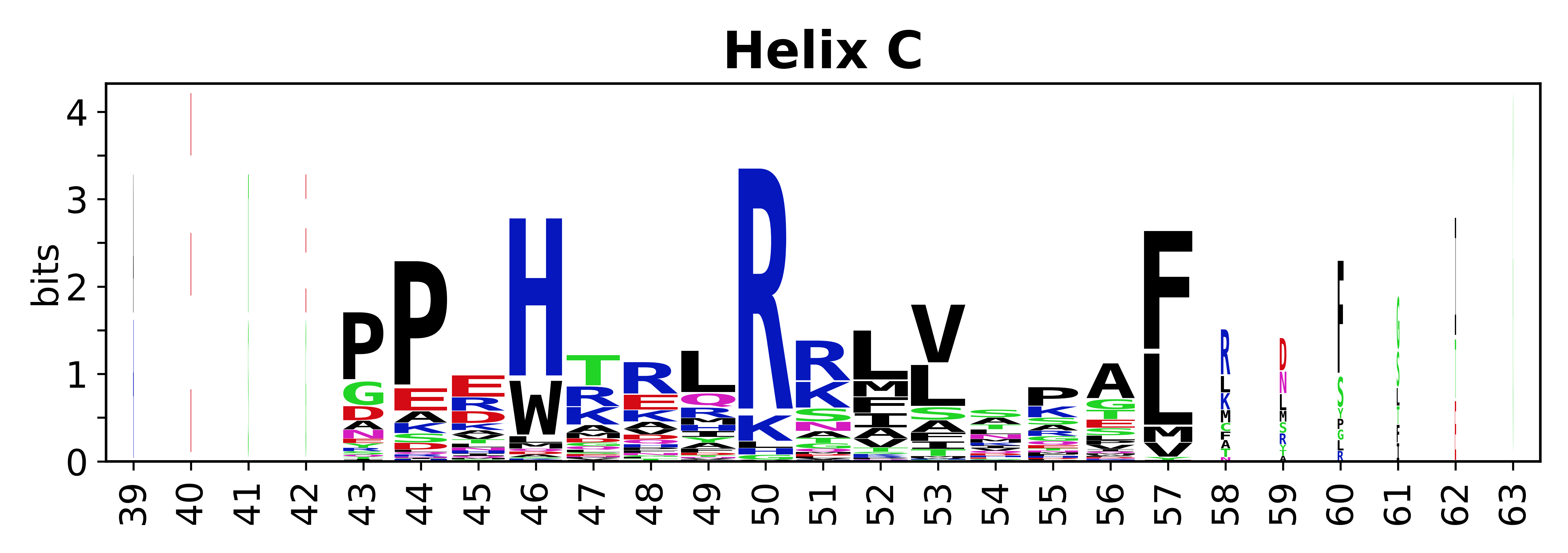
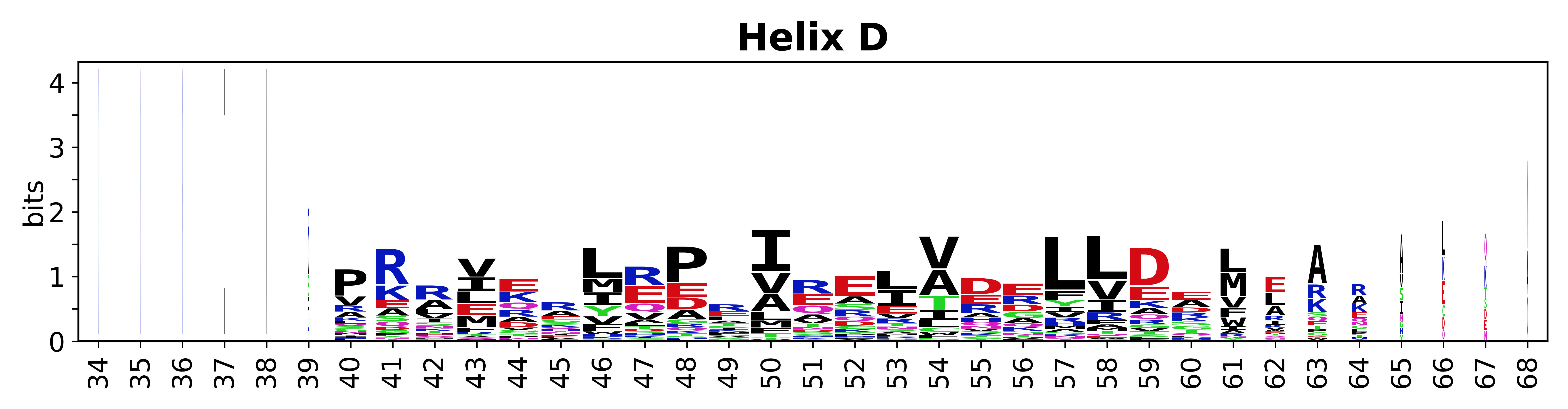
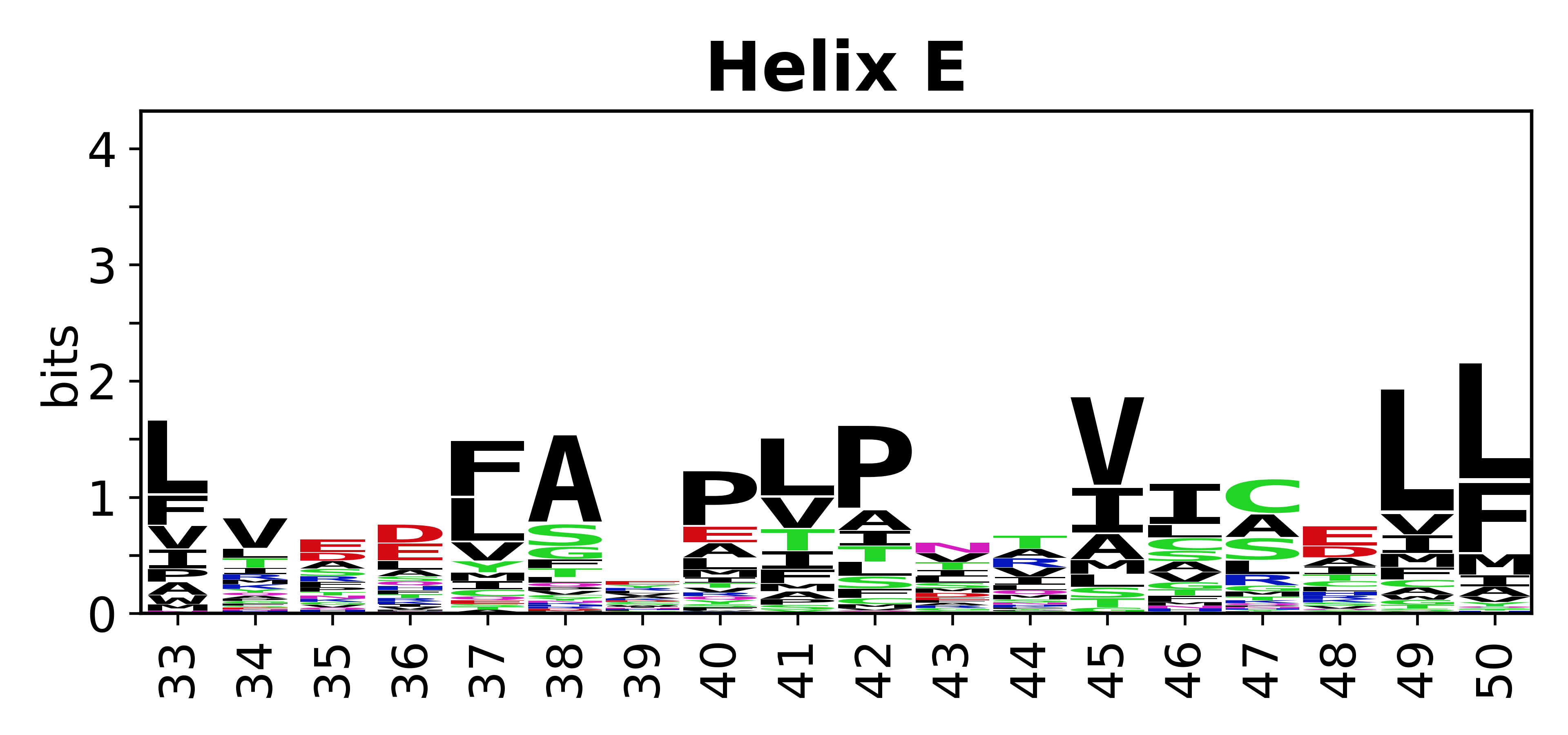
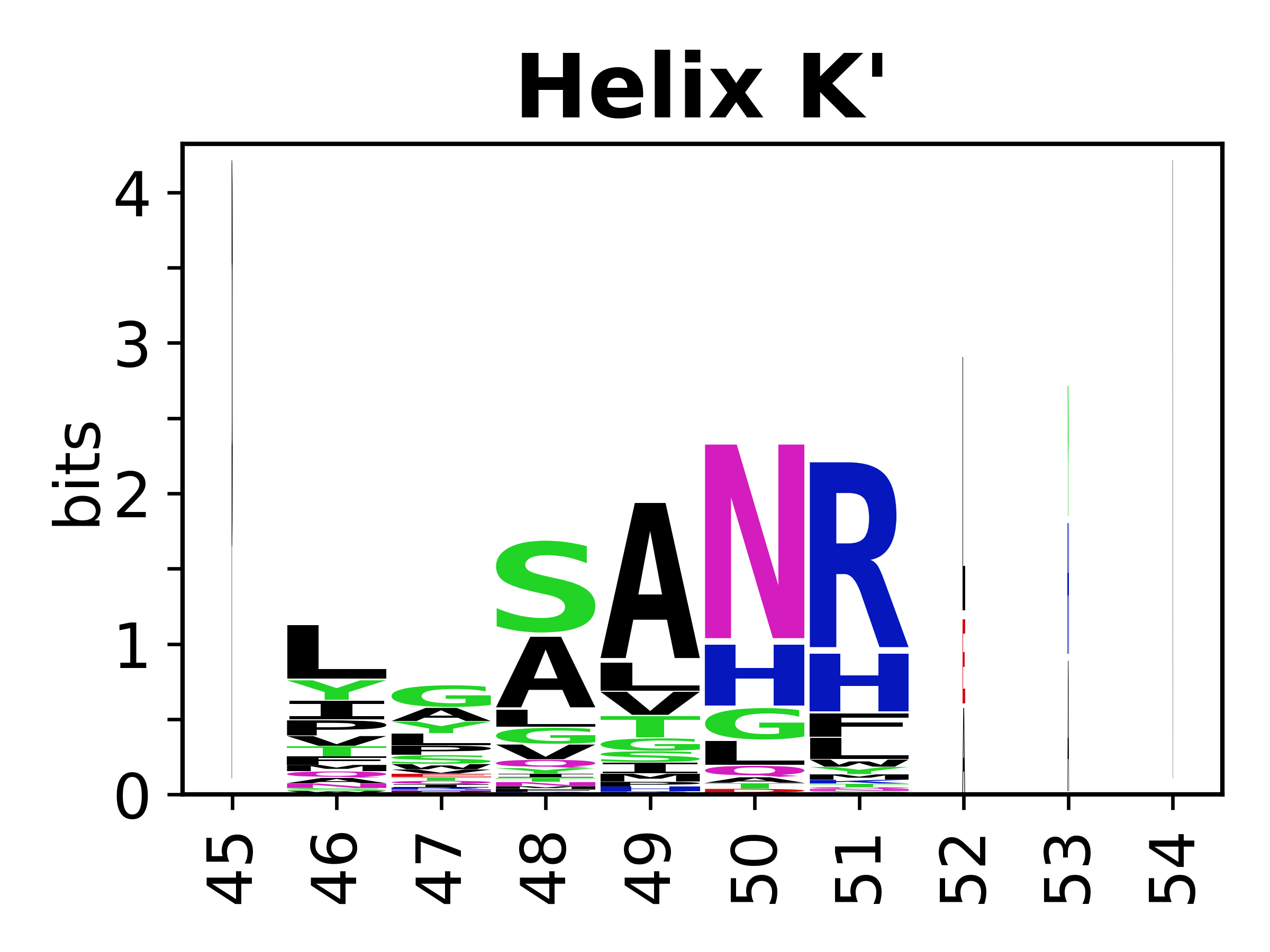
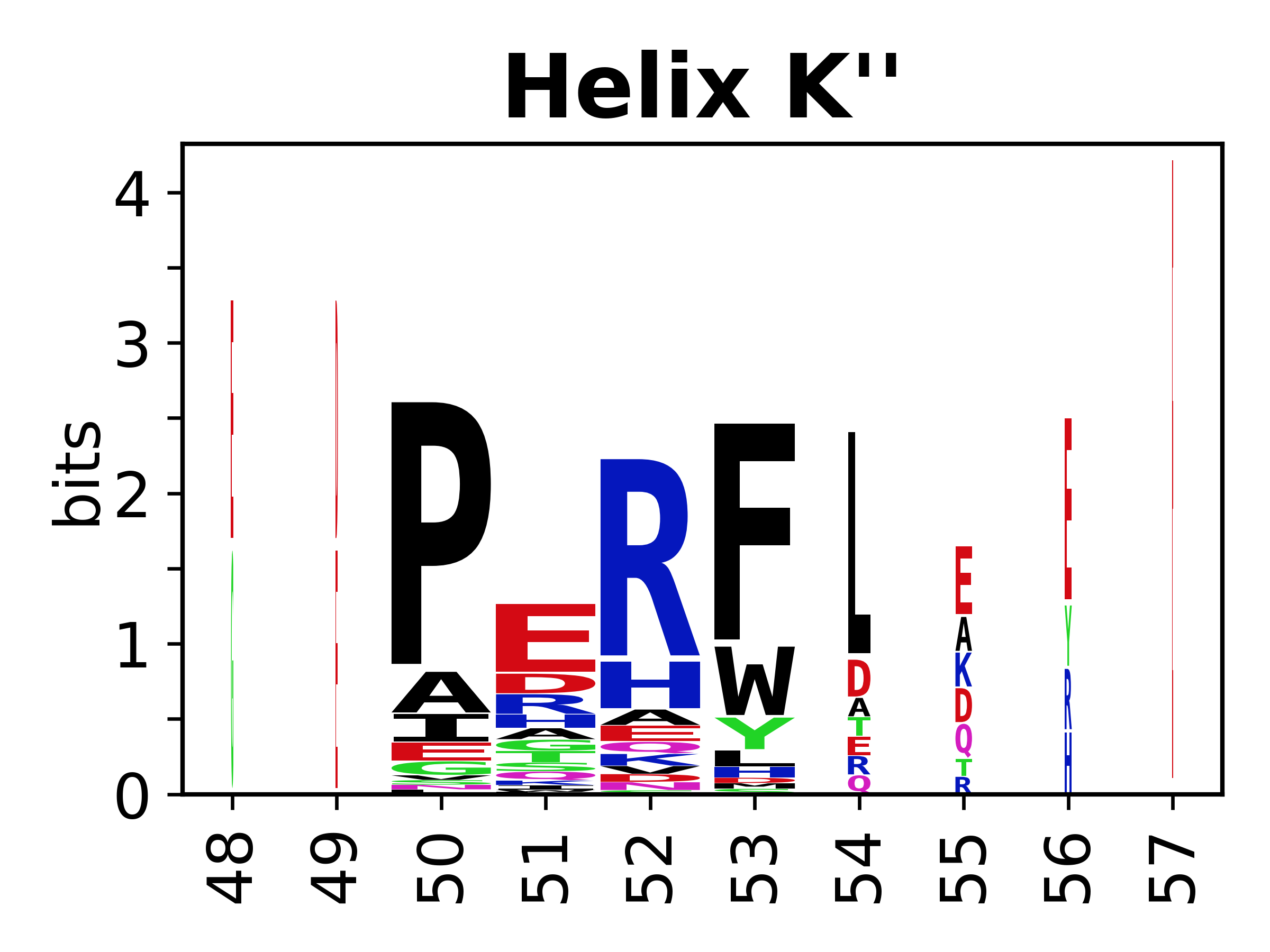
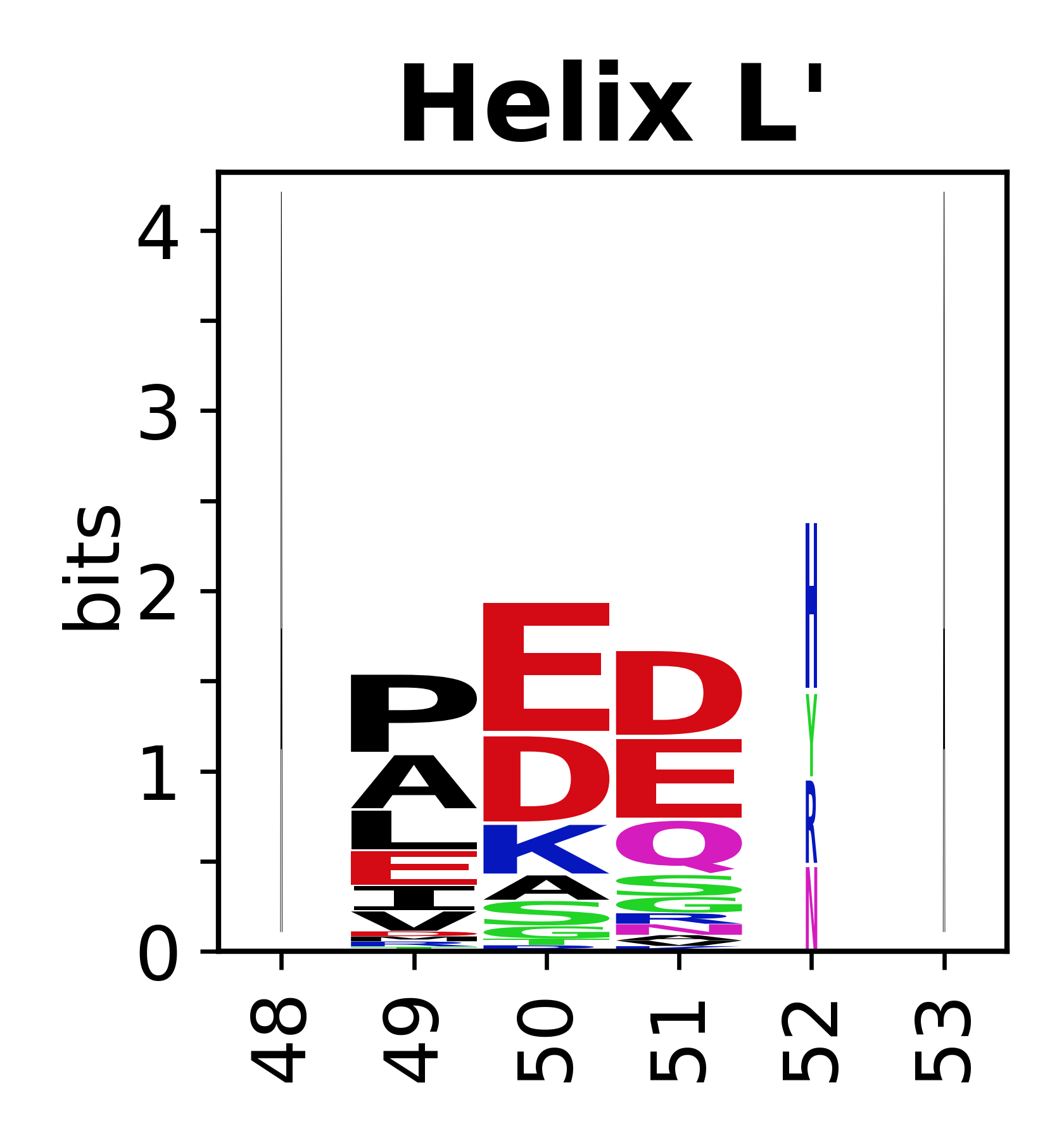
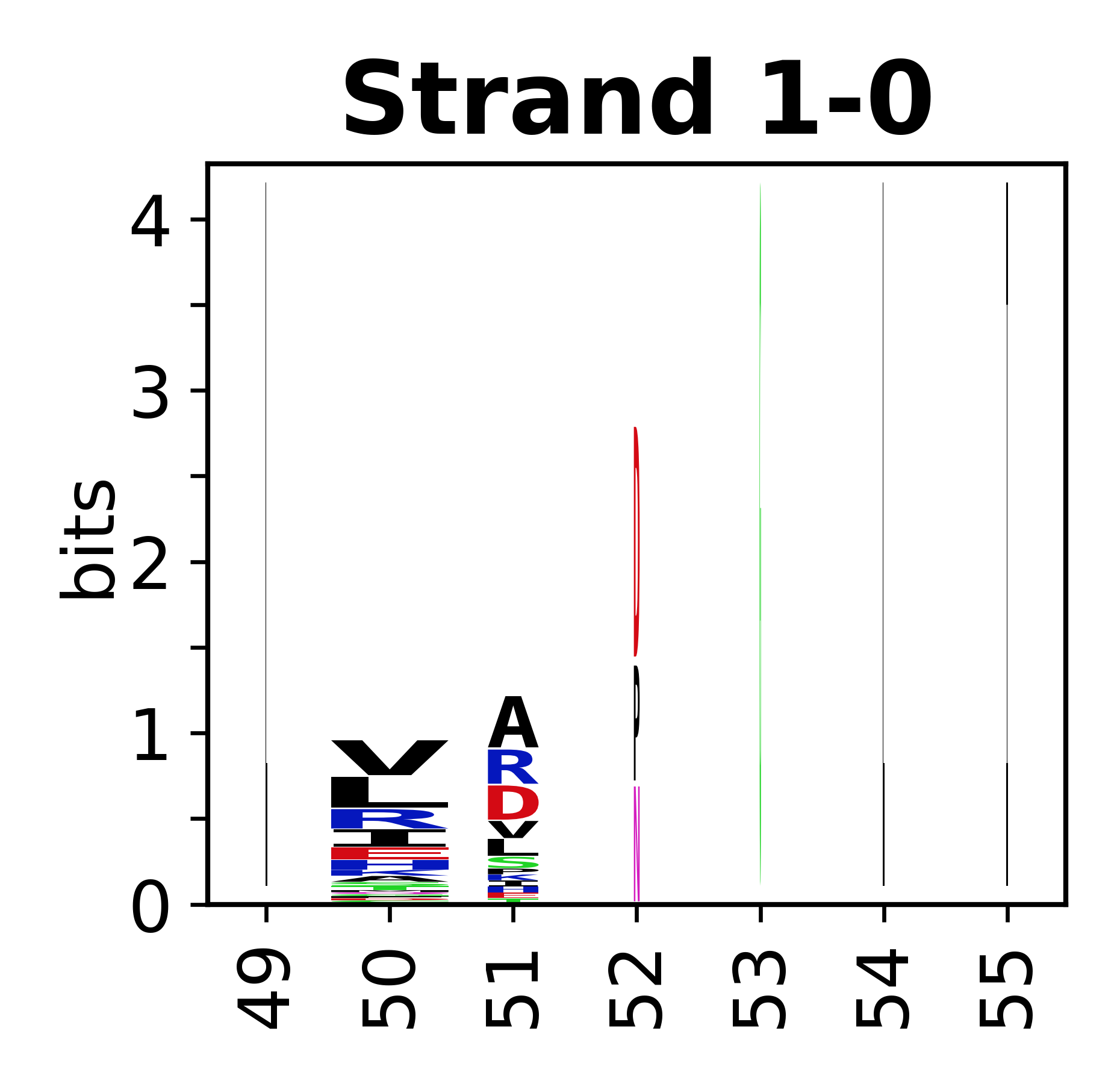
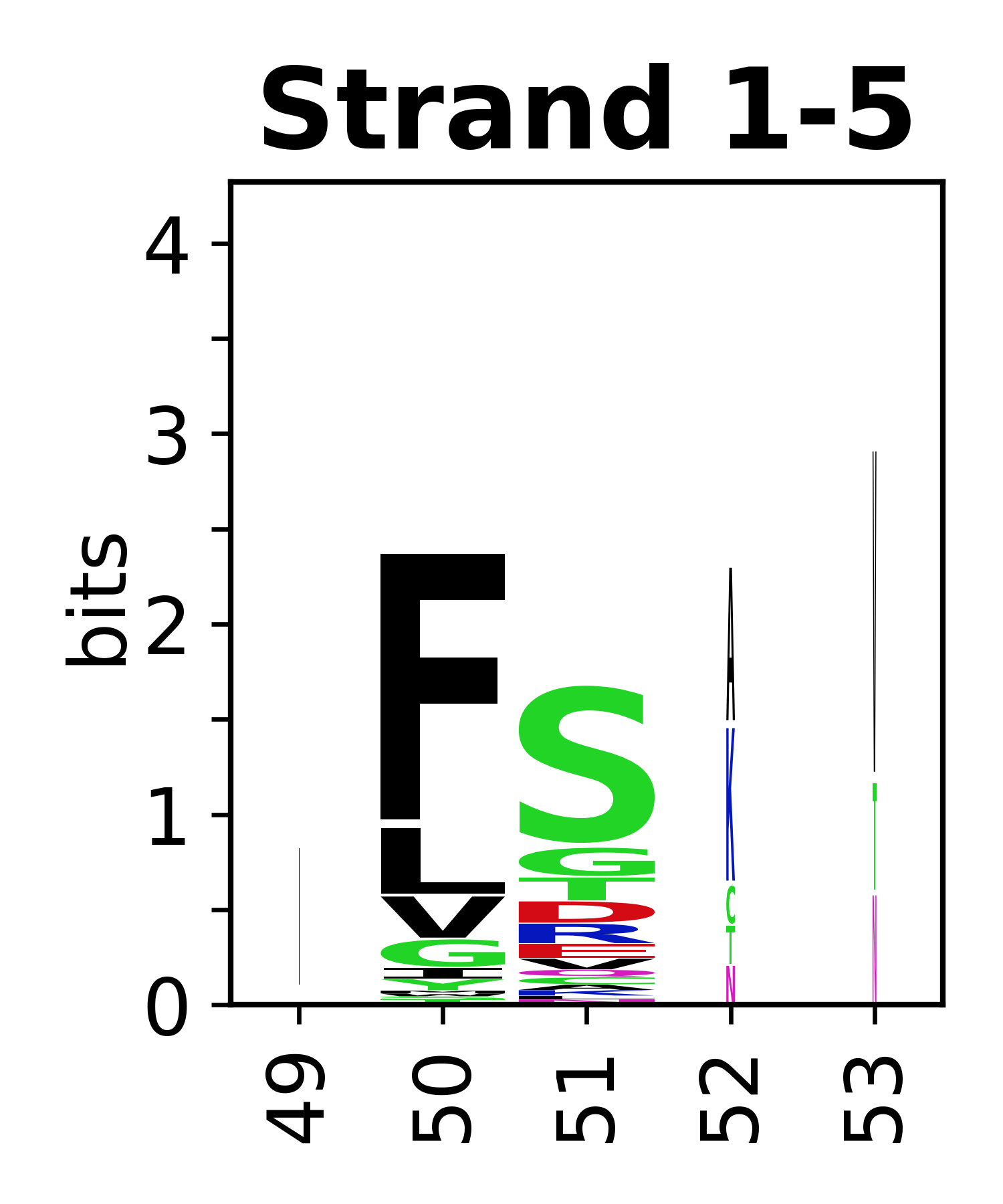
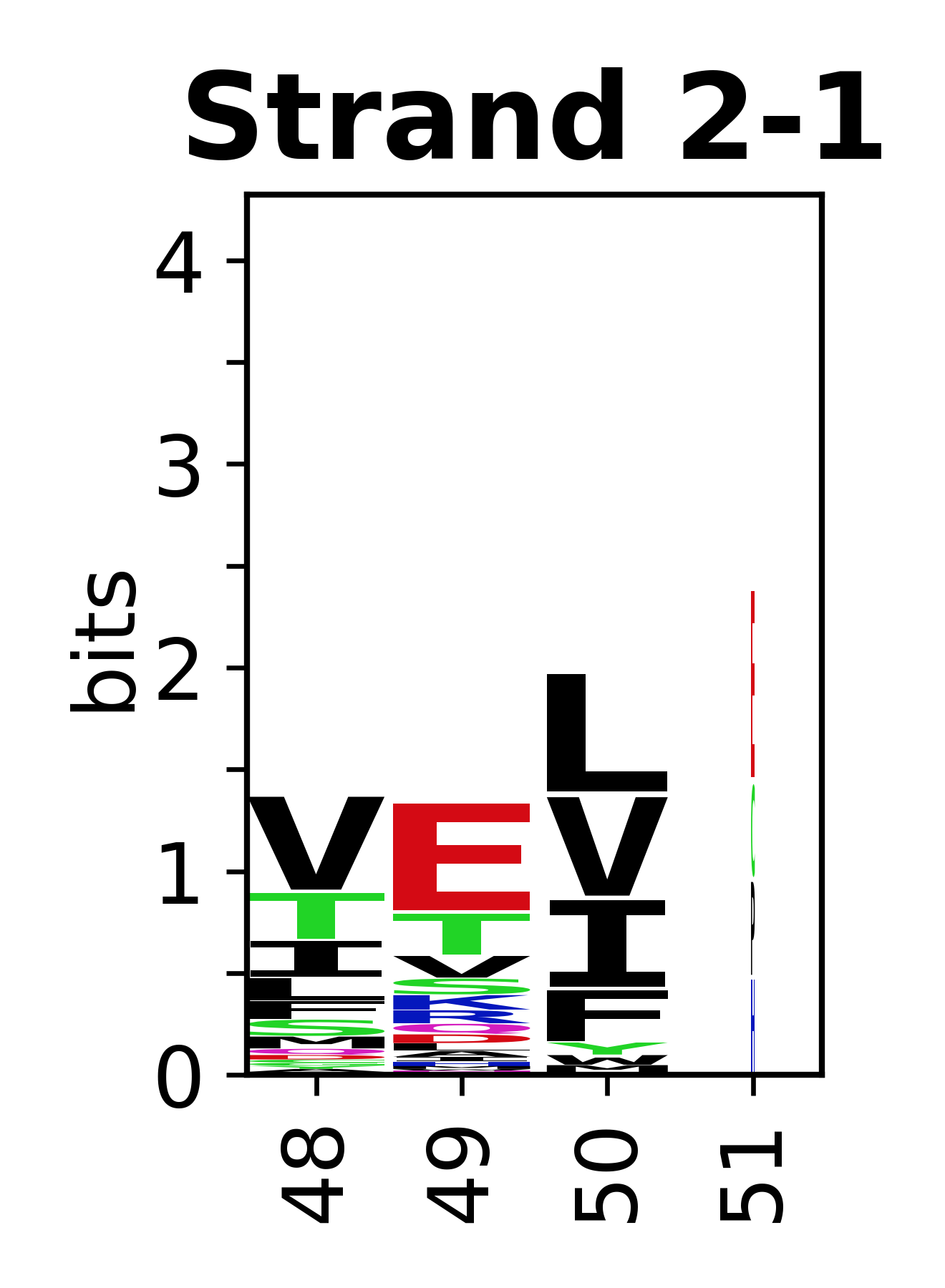
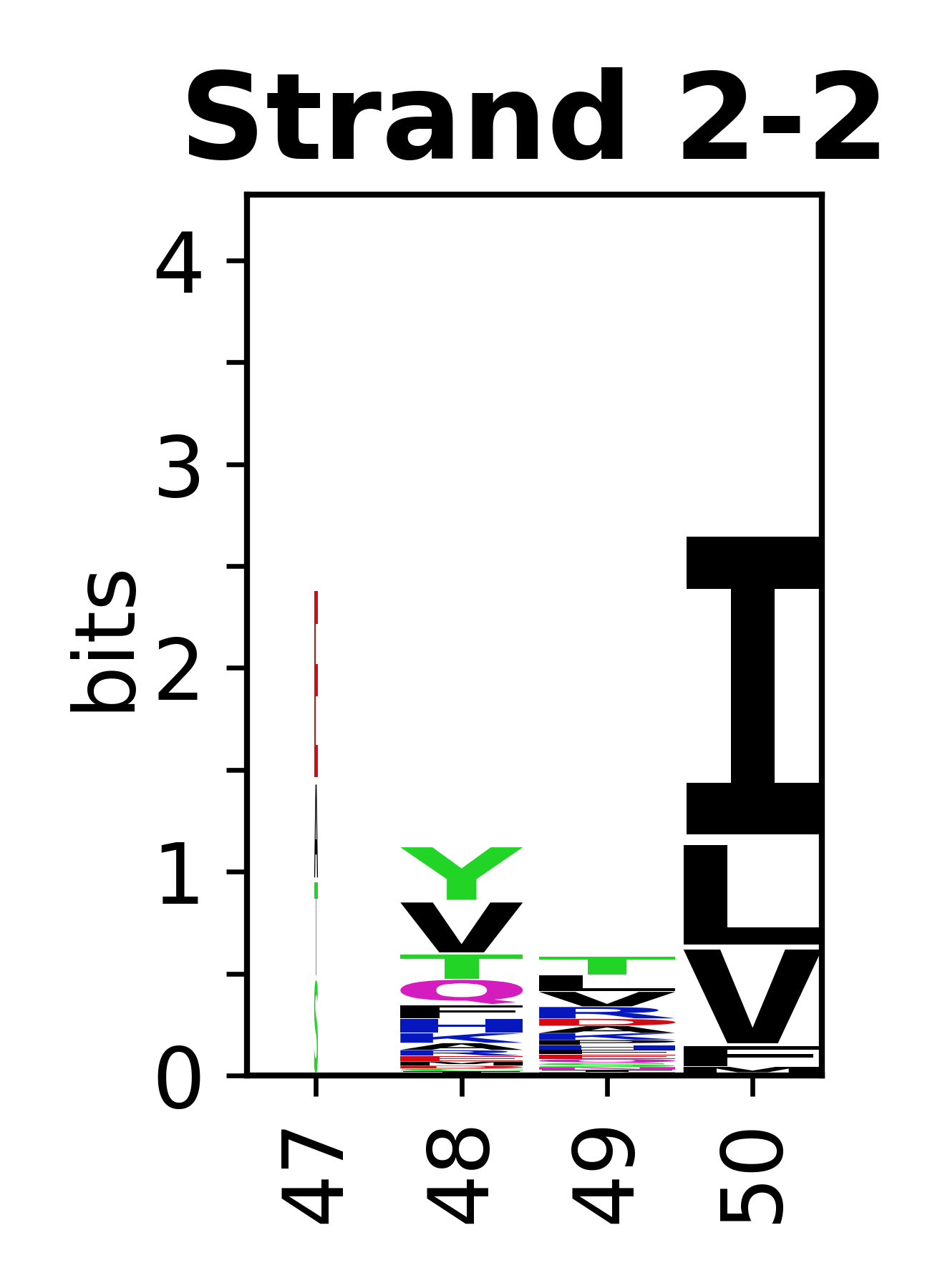
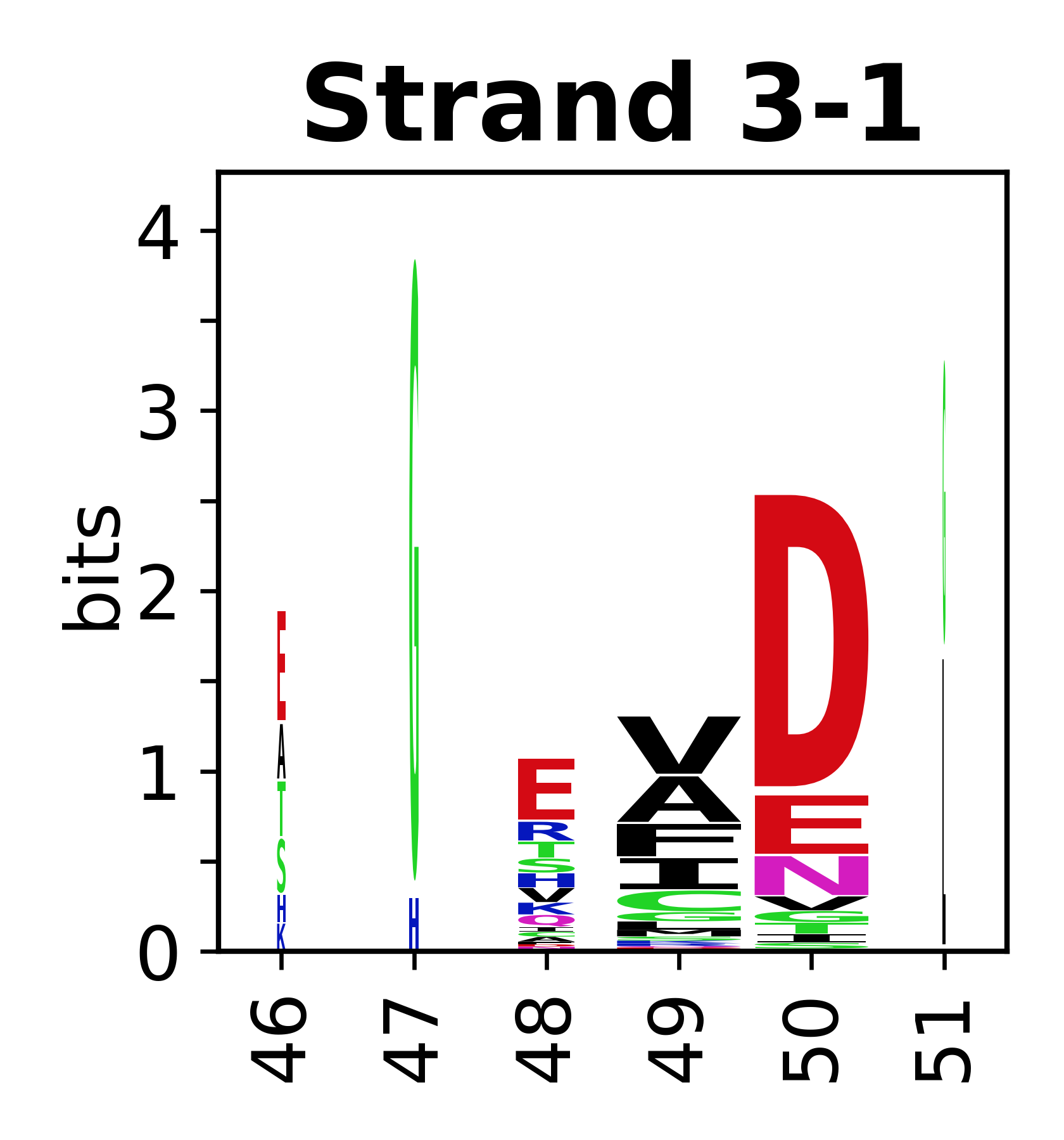
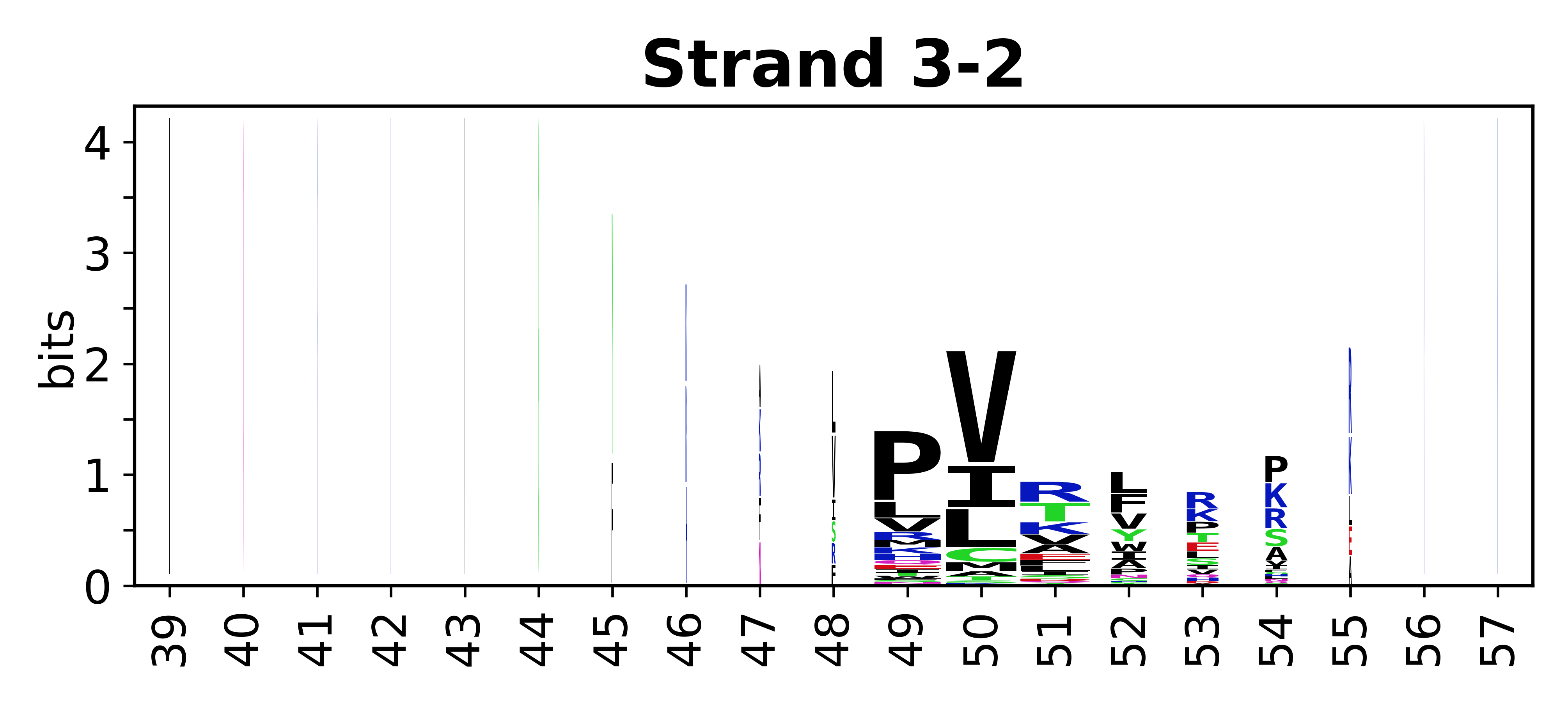
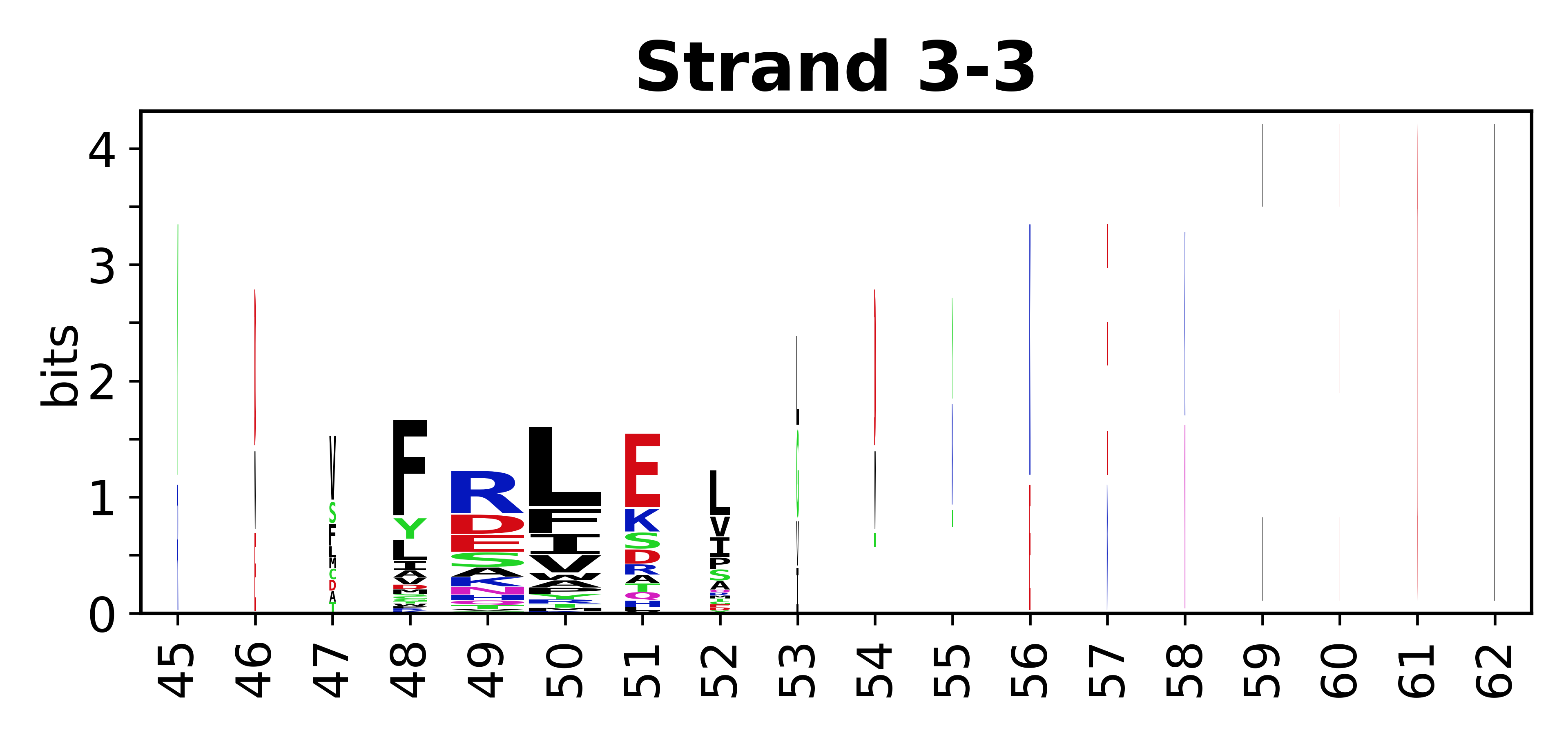
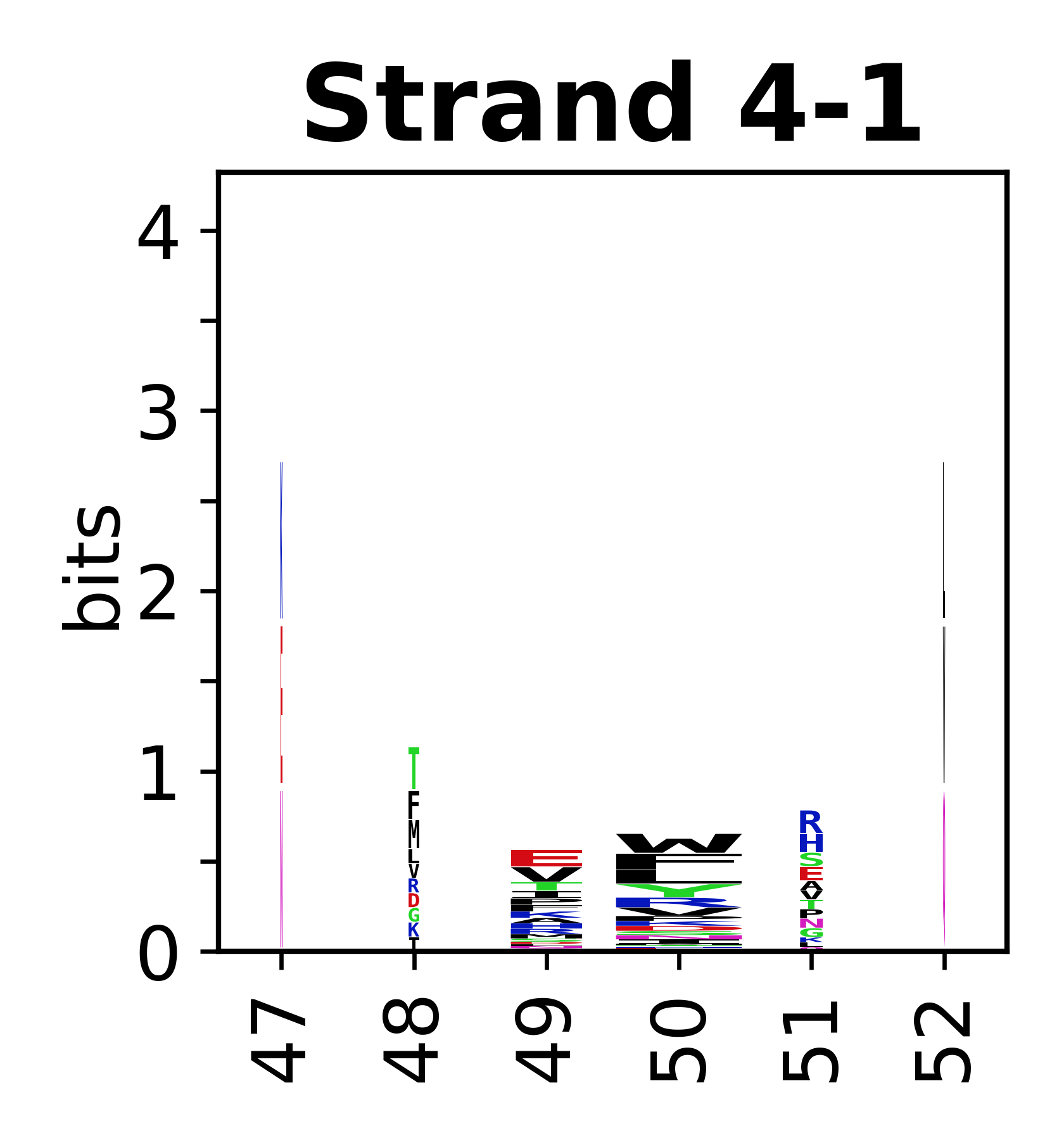
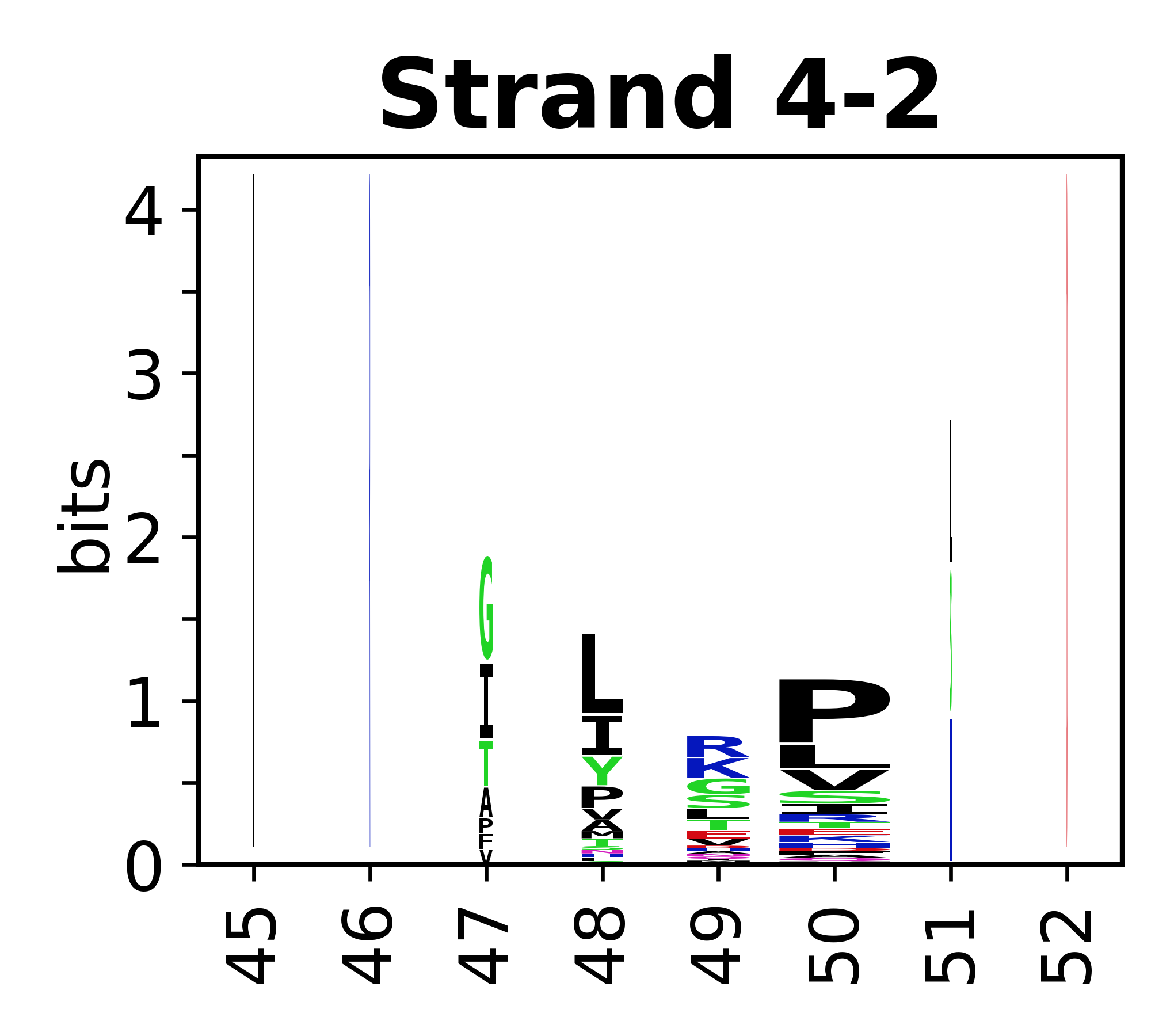
Sequence of SSEs
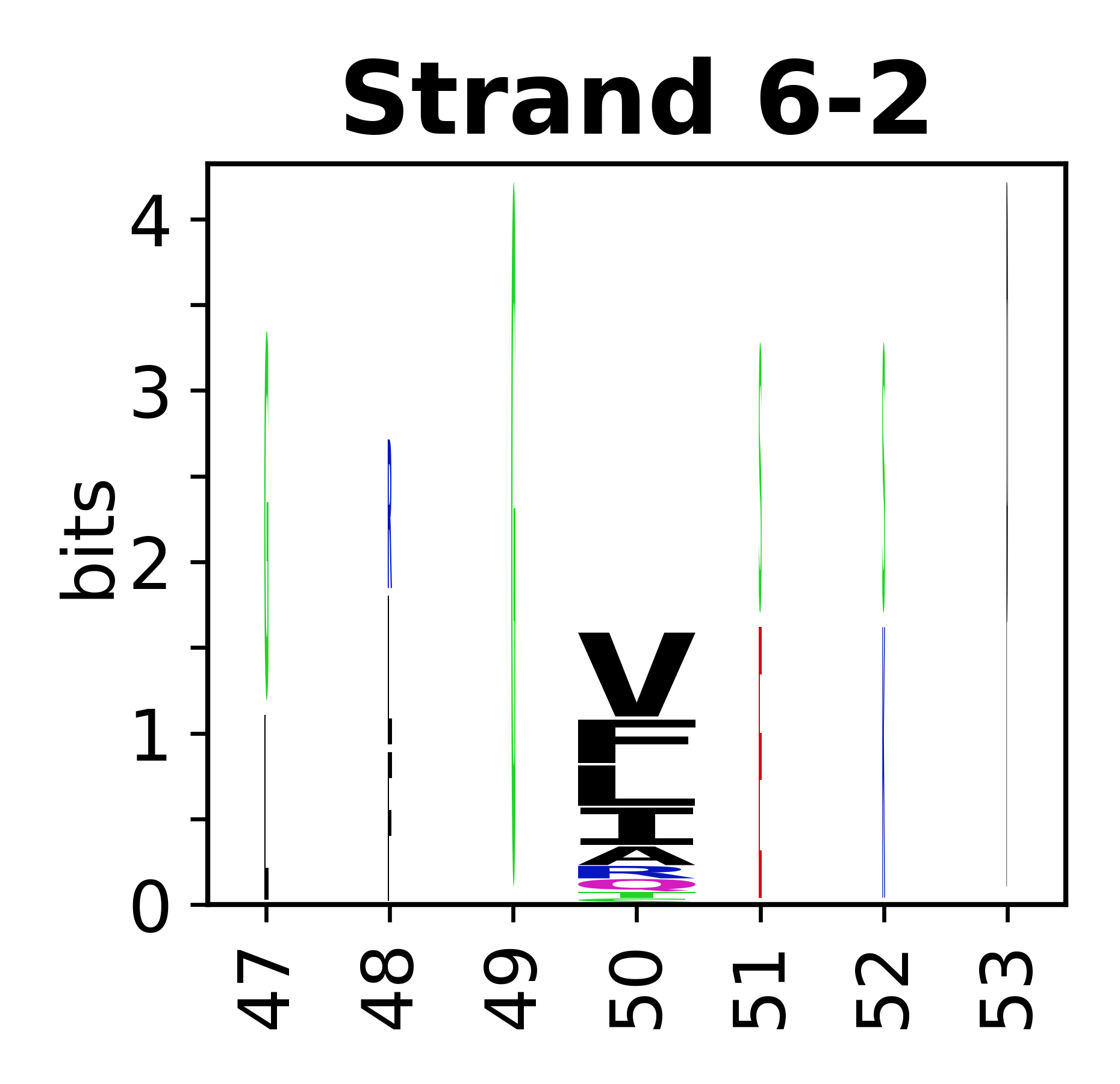
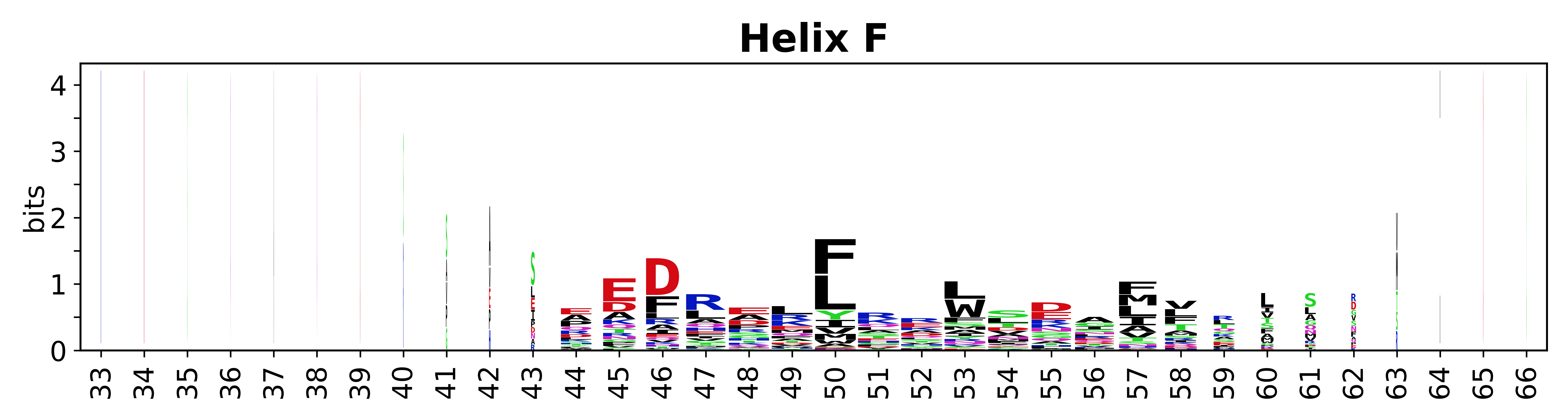
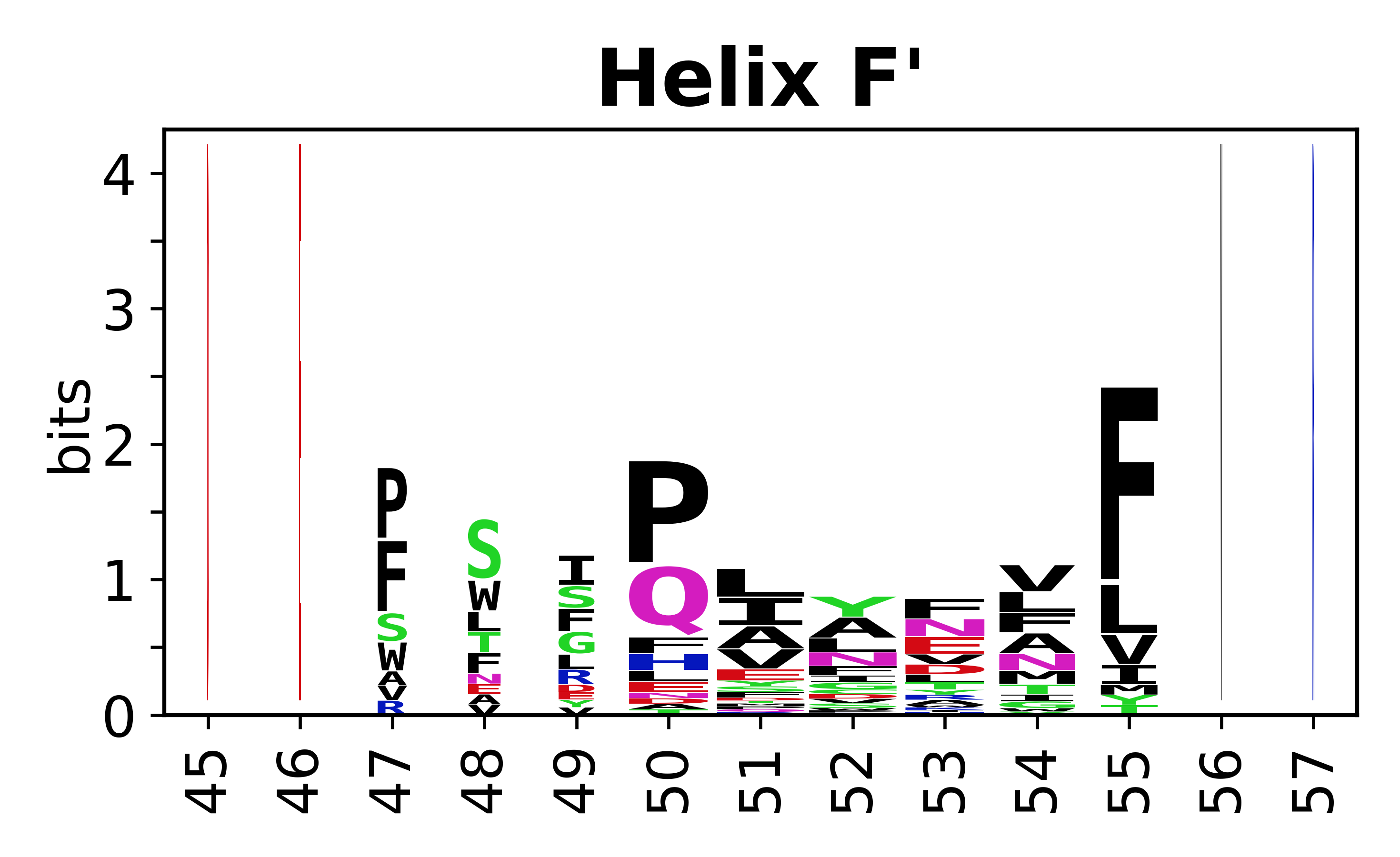
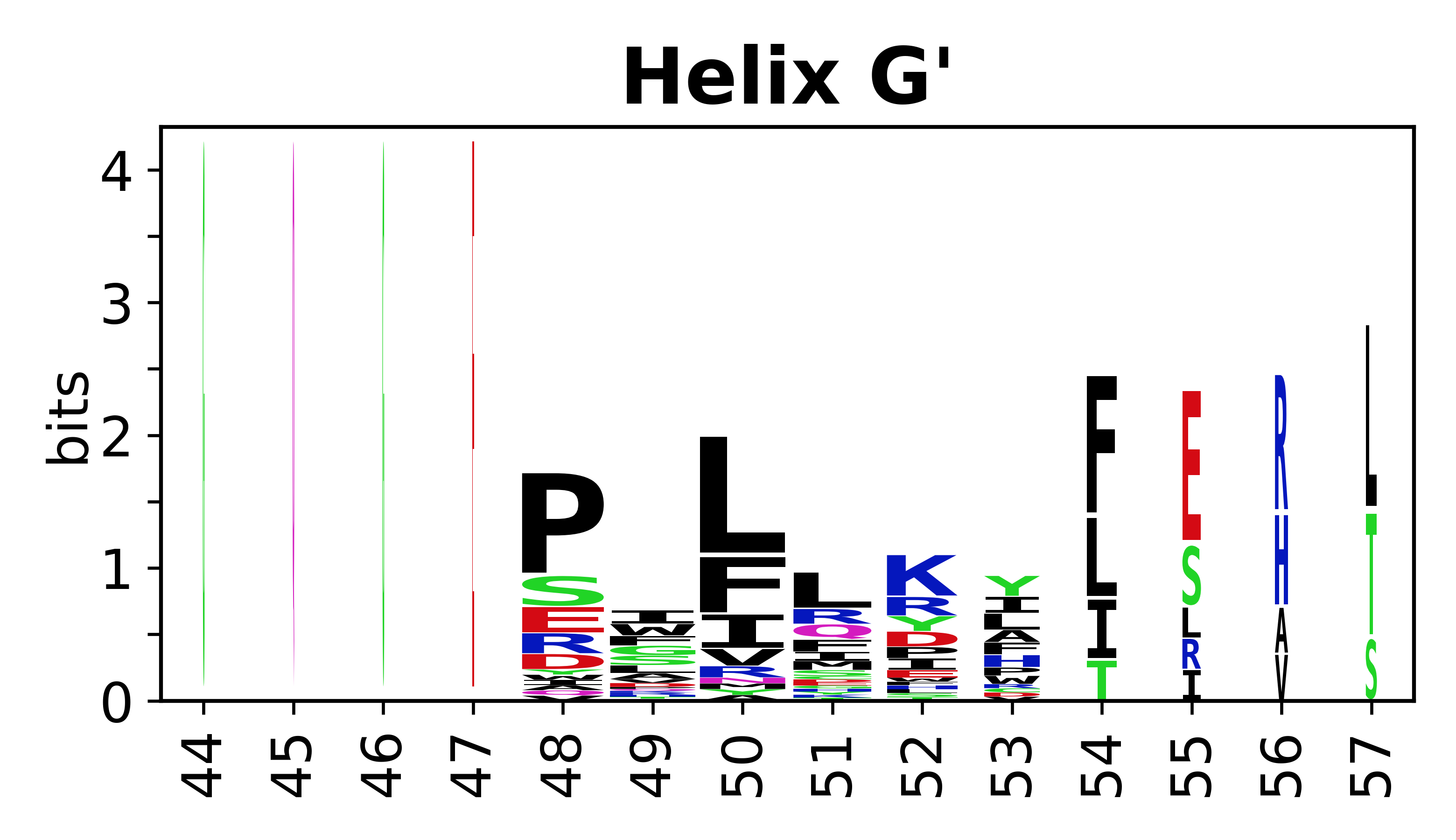
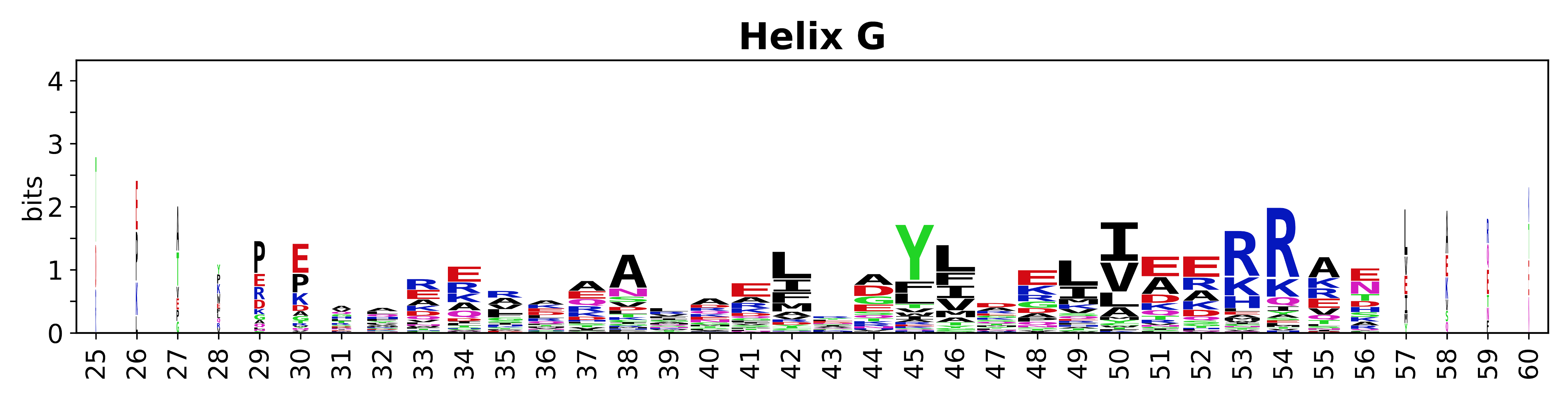
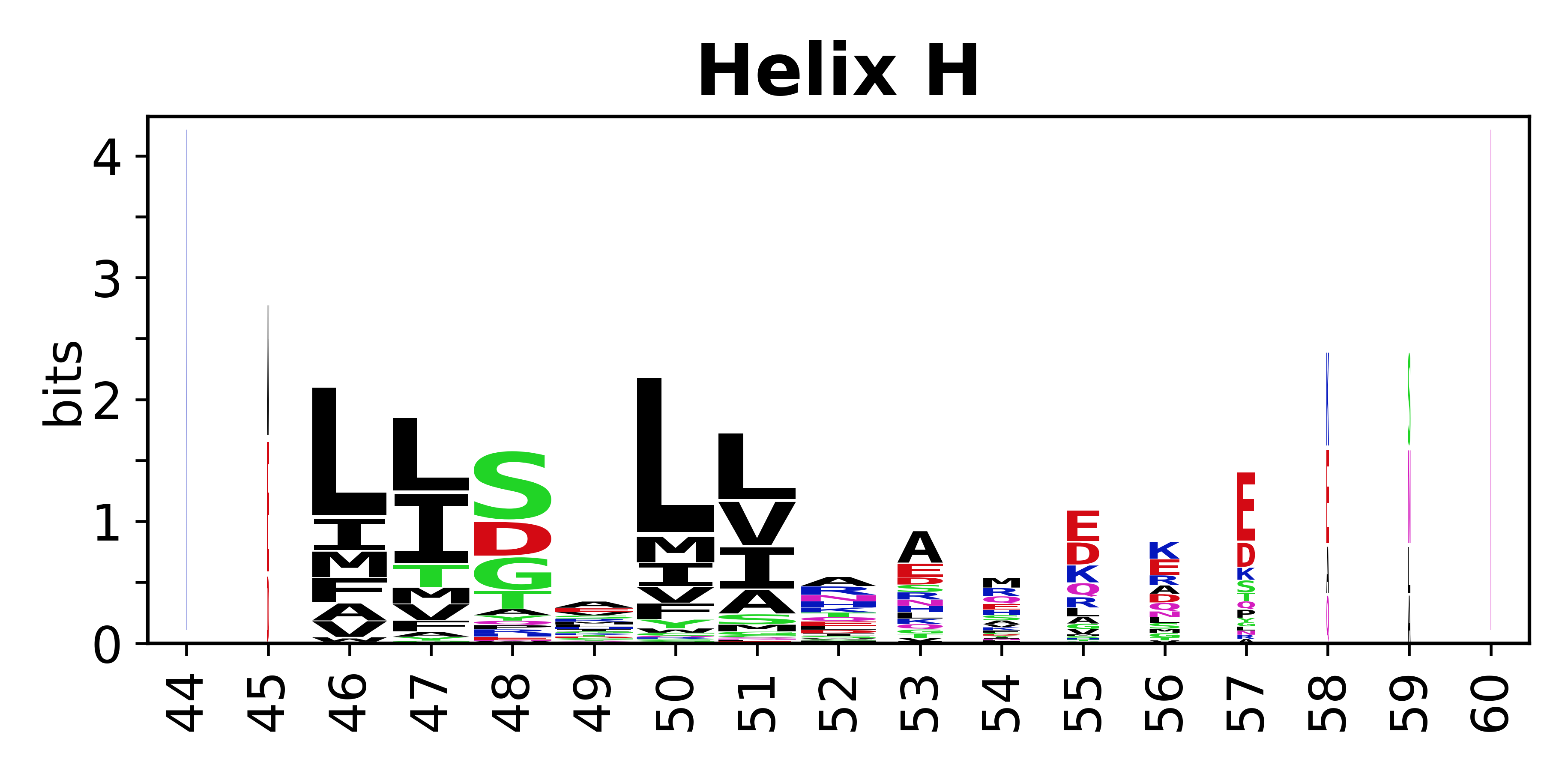
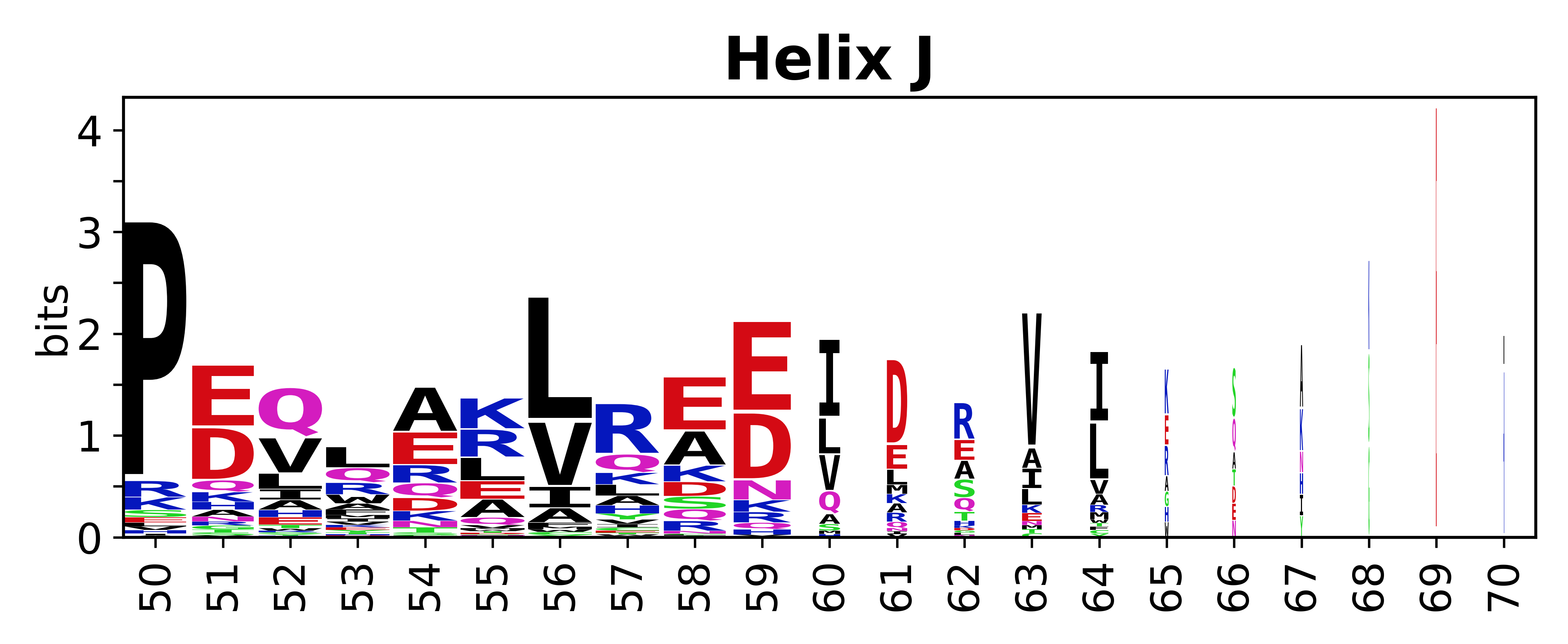
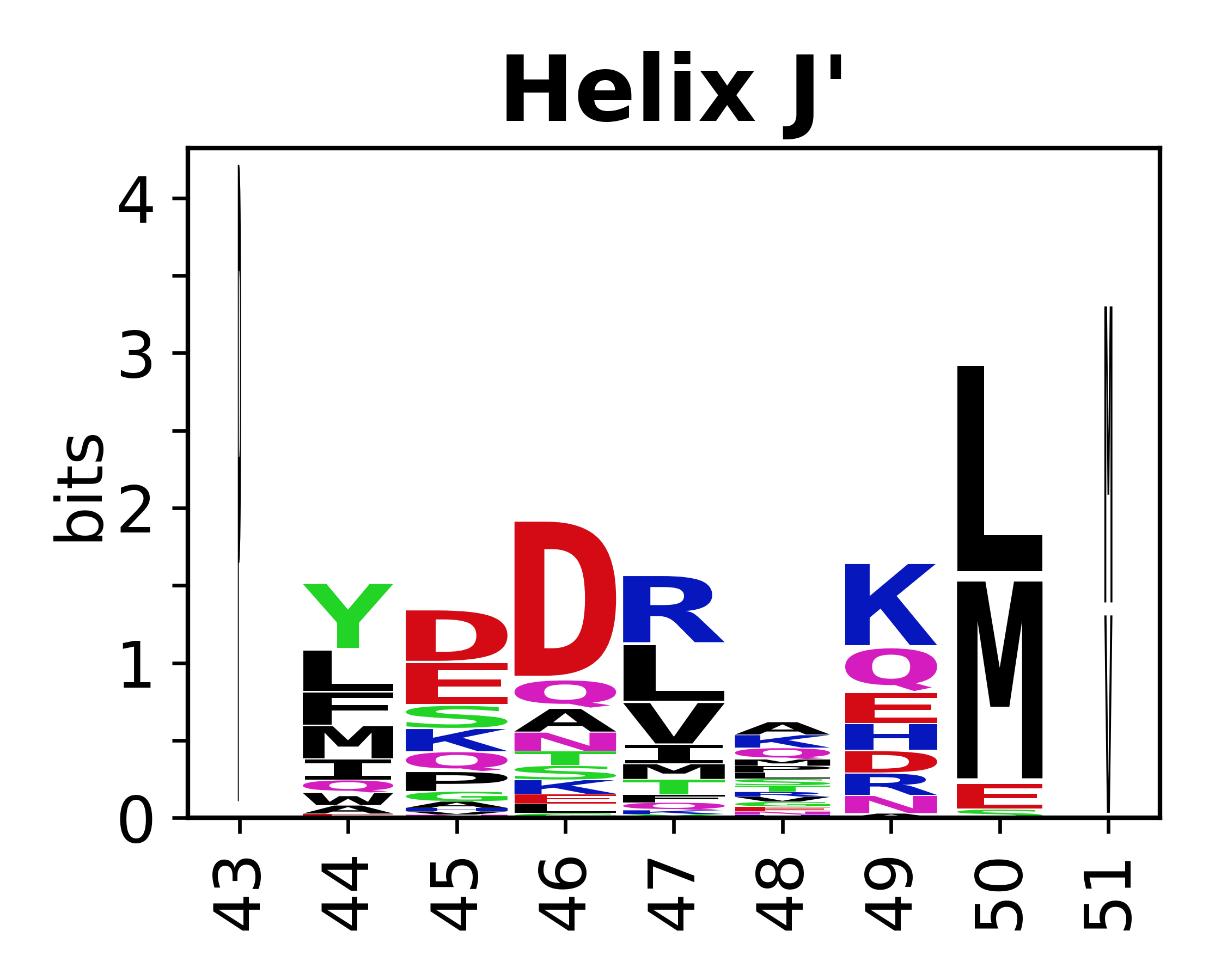
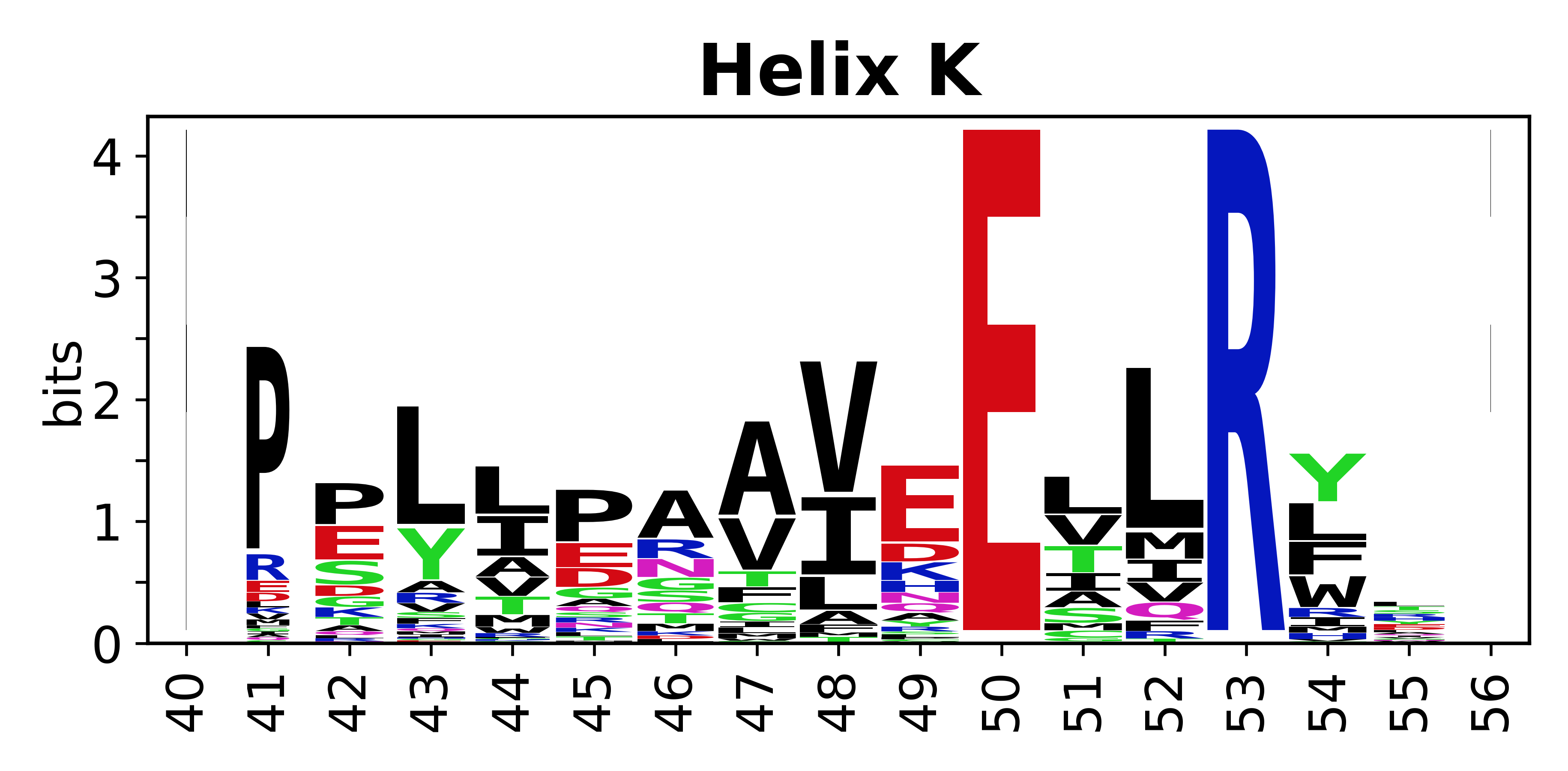
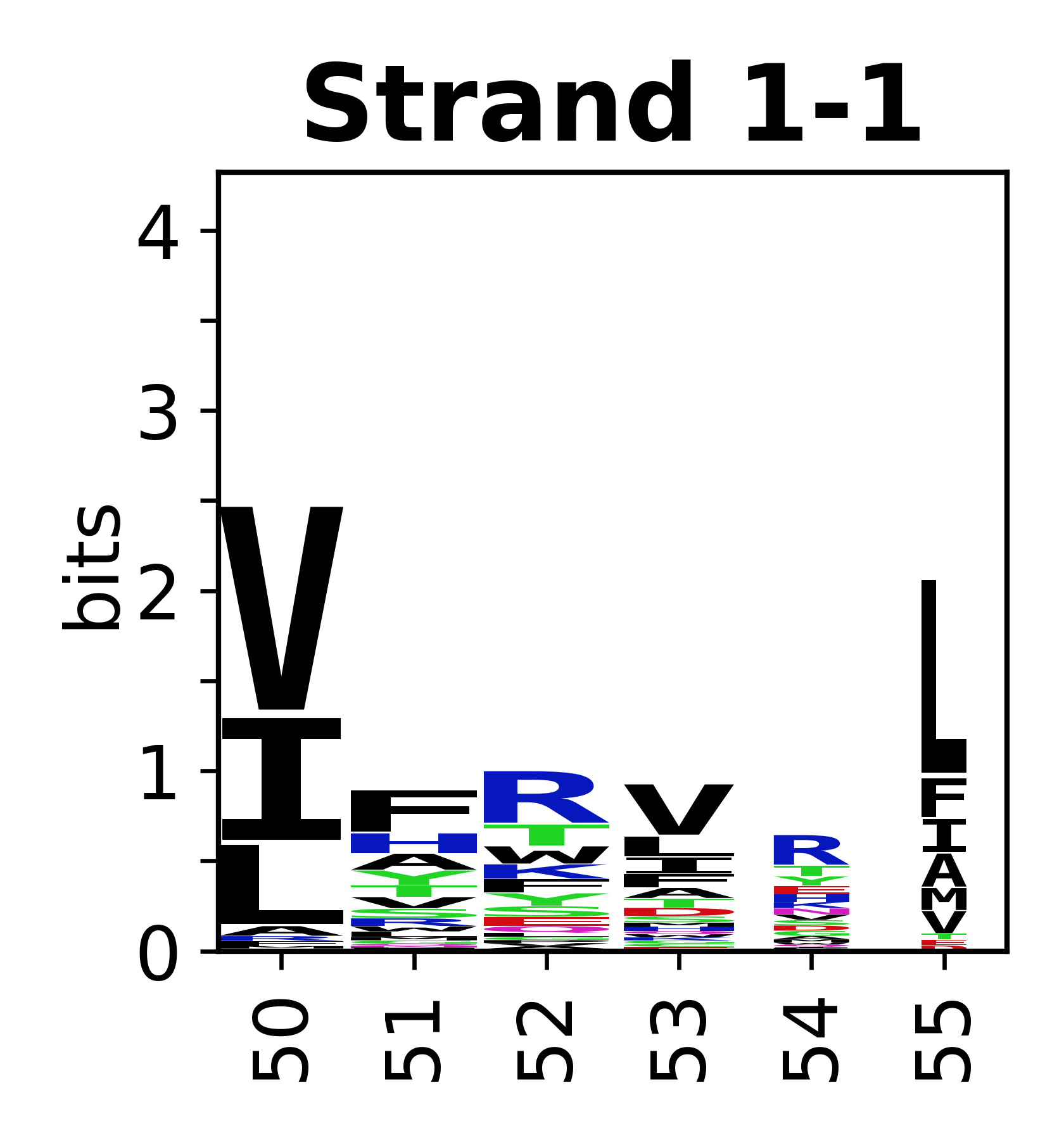
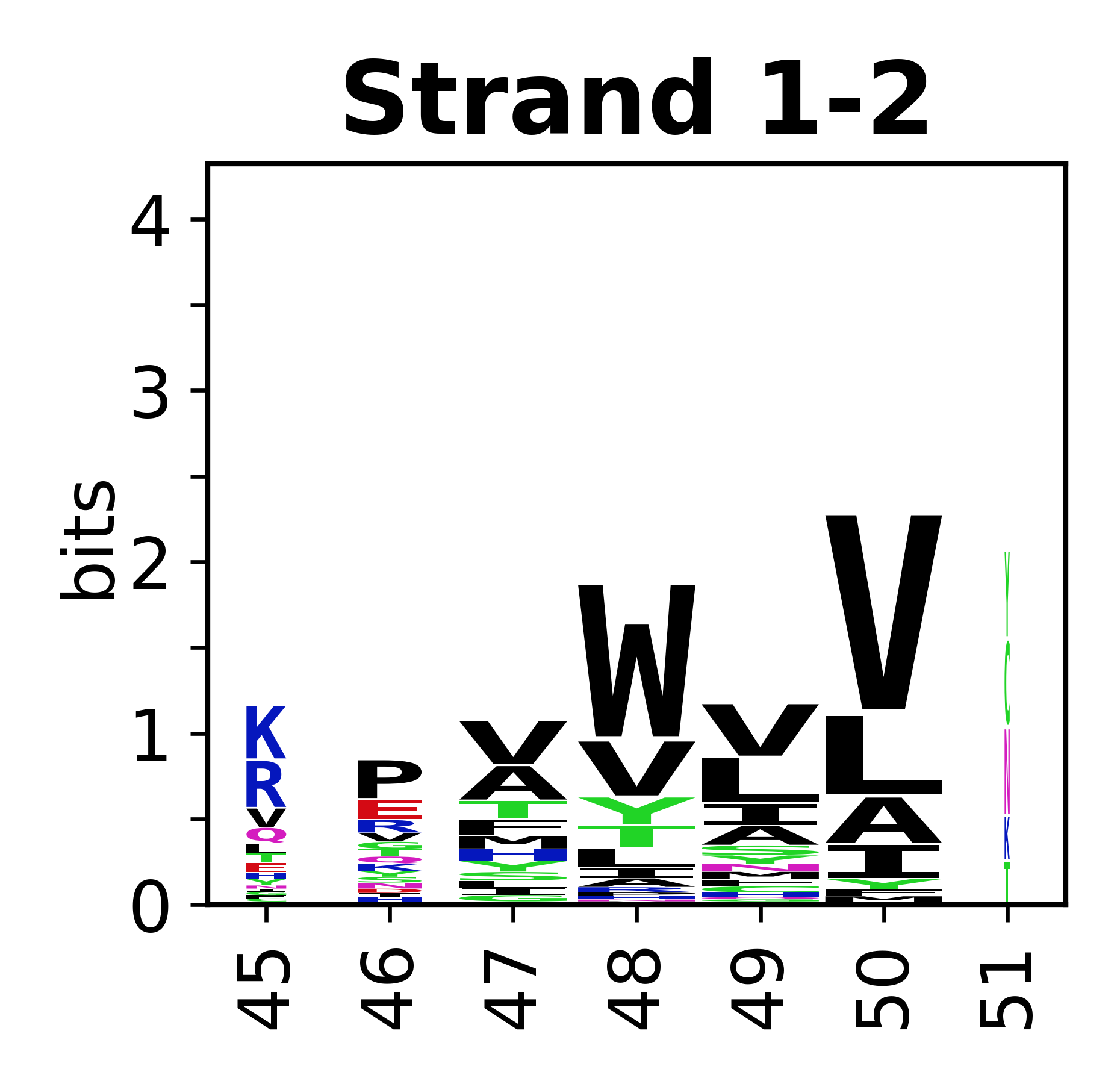
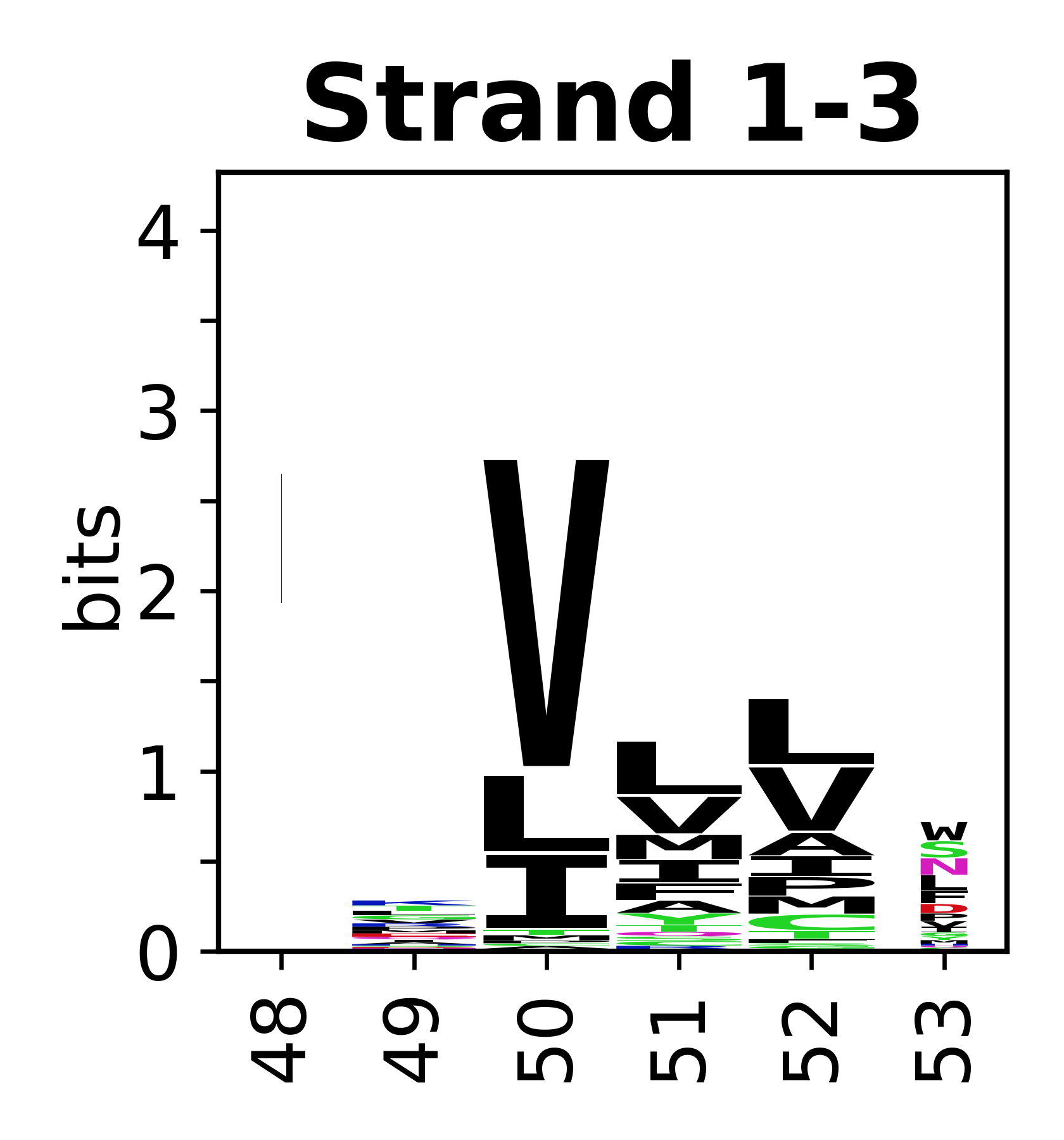
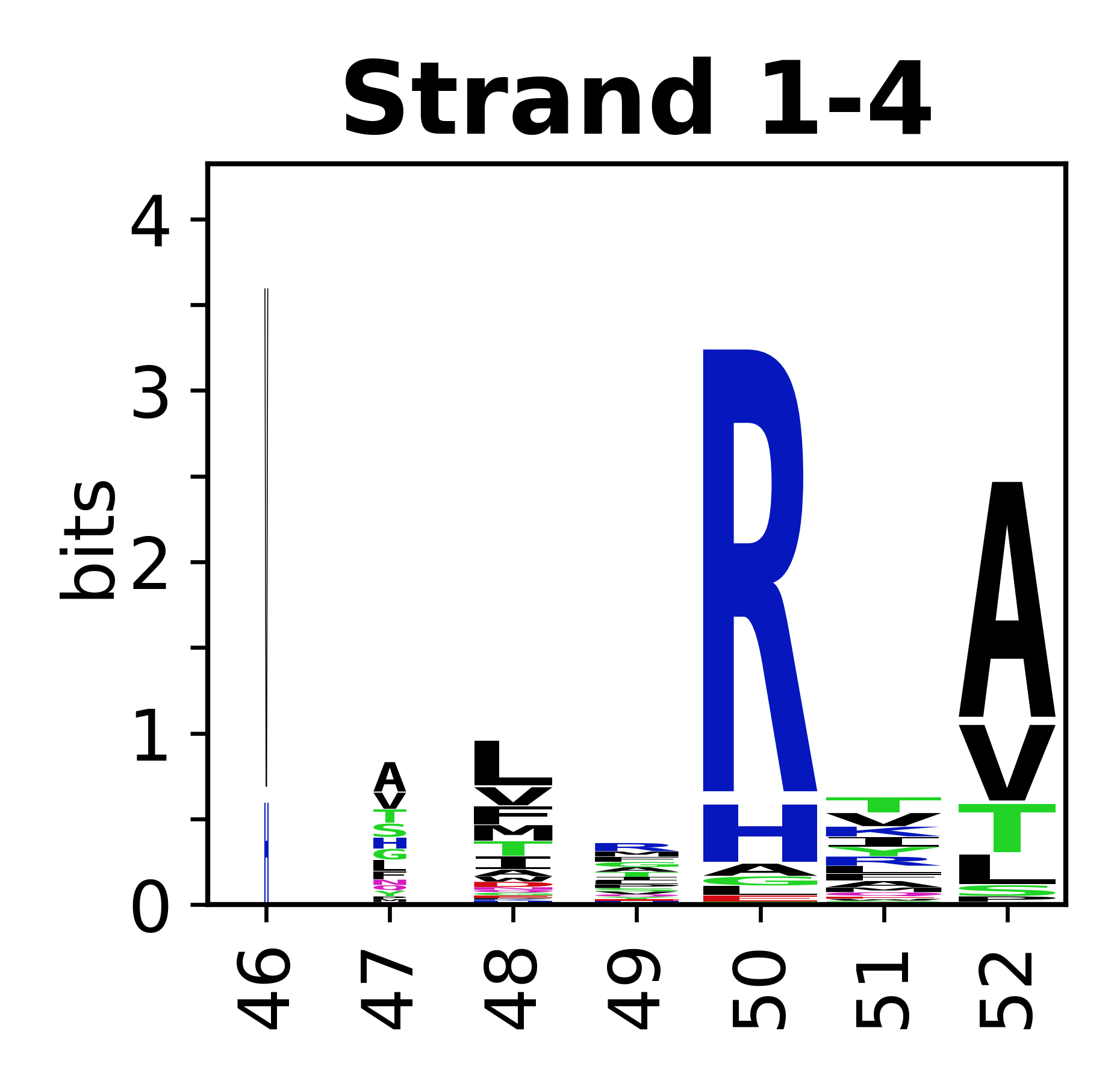
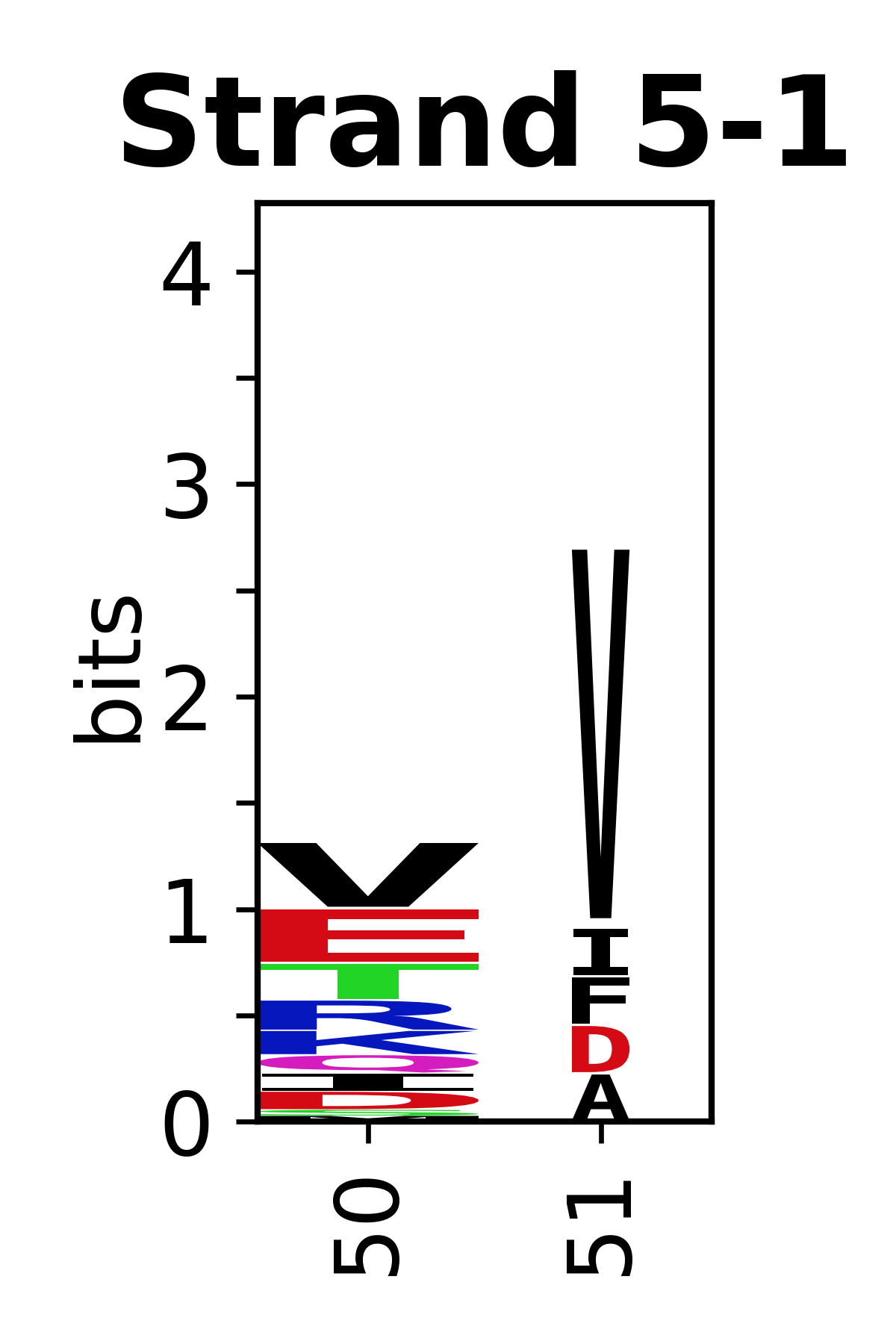
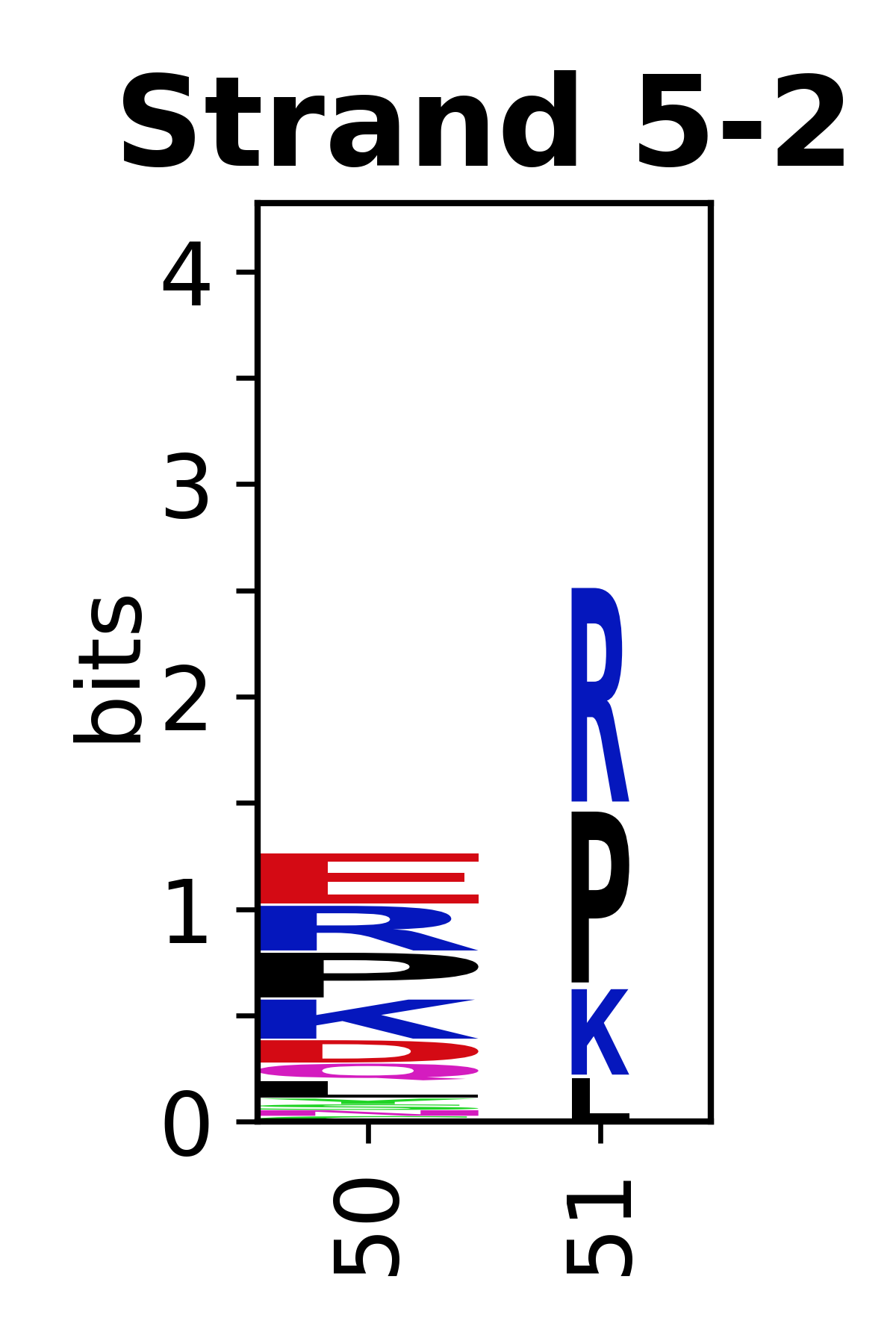
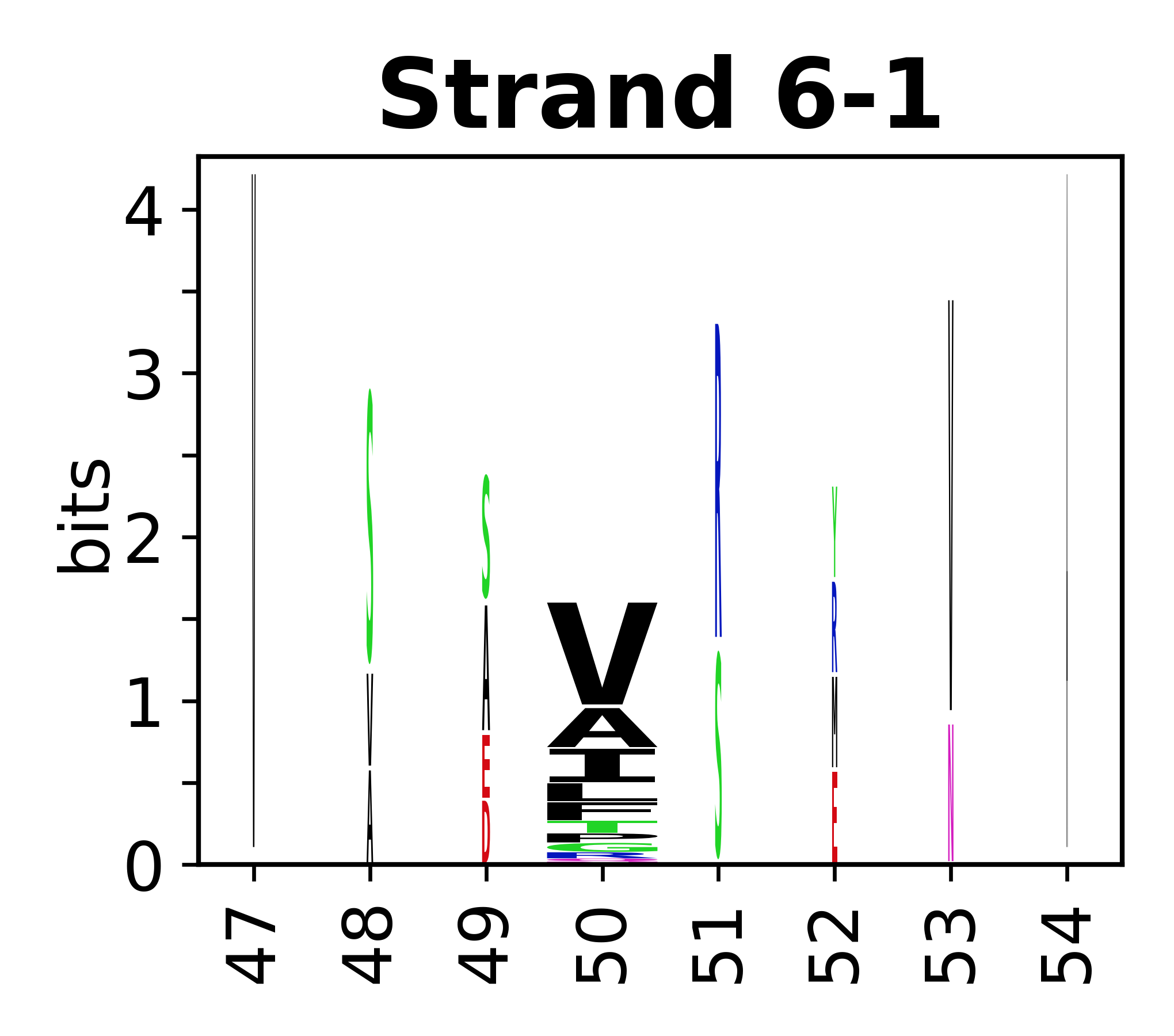
The amino acid sequences for each SSE can be aligned and used to produce a sequence logo. Where the sequence conservation is sufficient, we can establish a generic numbering scheme: the most conserved residue in helix X serves as its reference residue and is numbered as @X.50. The remaining residues in the helix are numbered accordingly.
- Helices
-
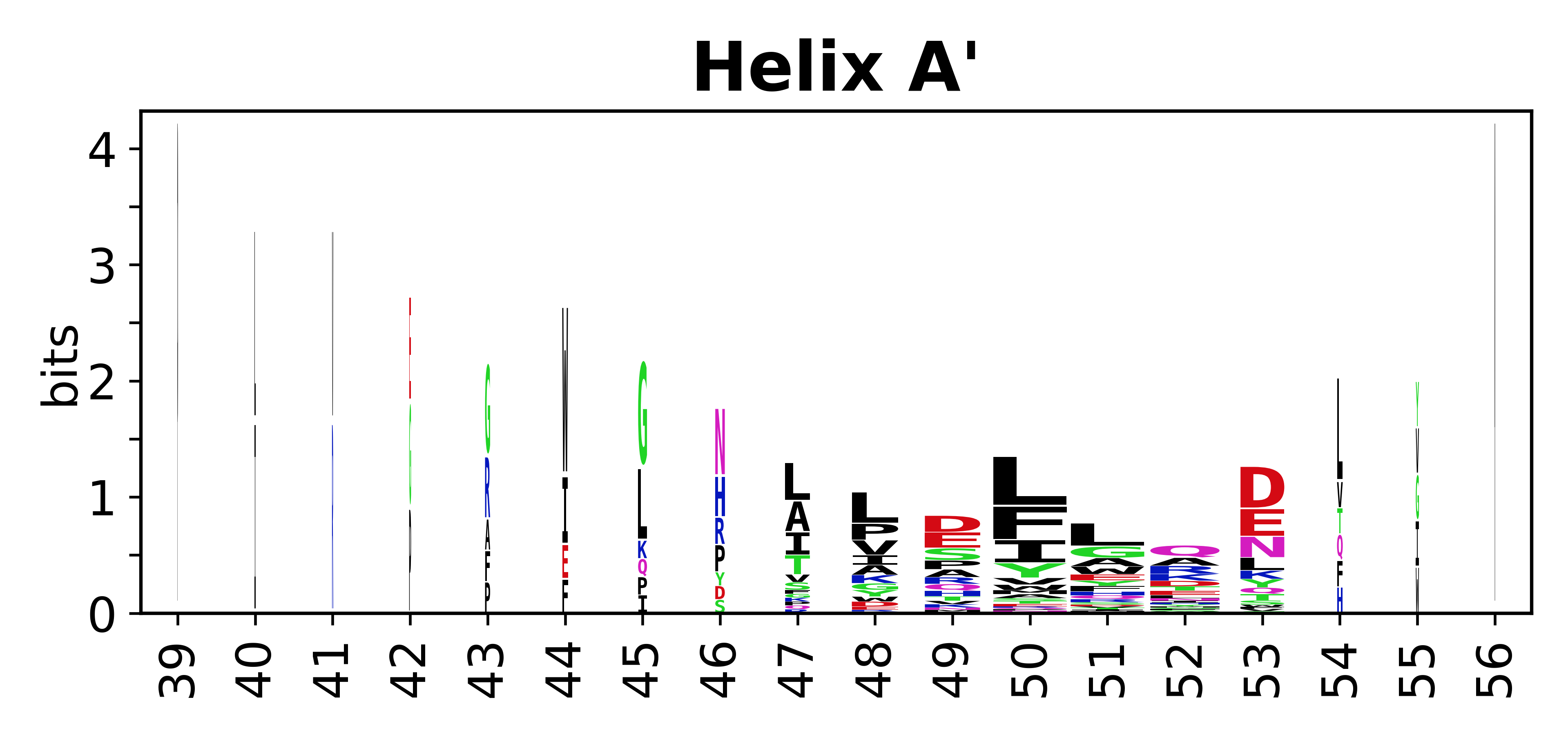
-

-
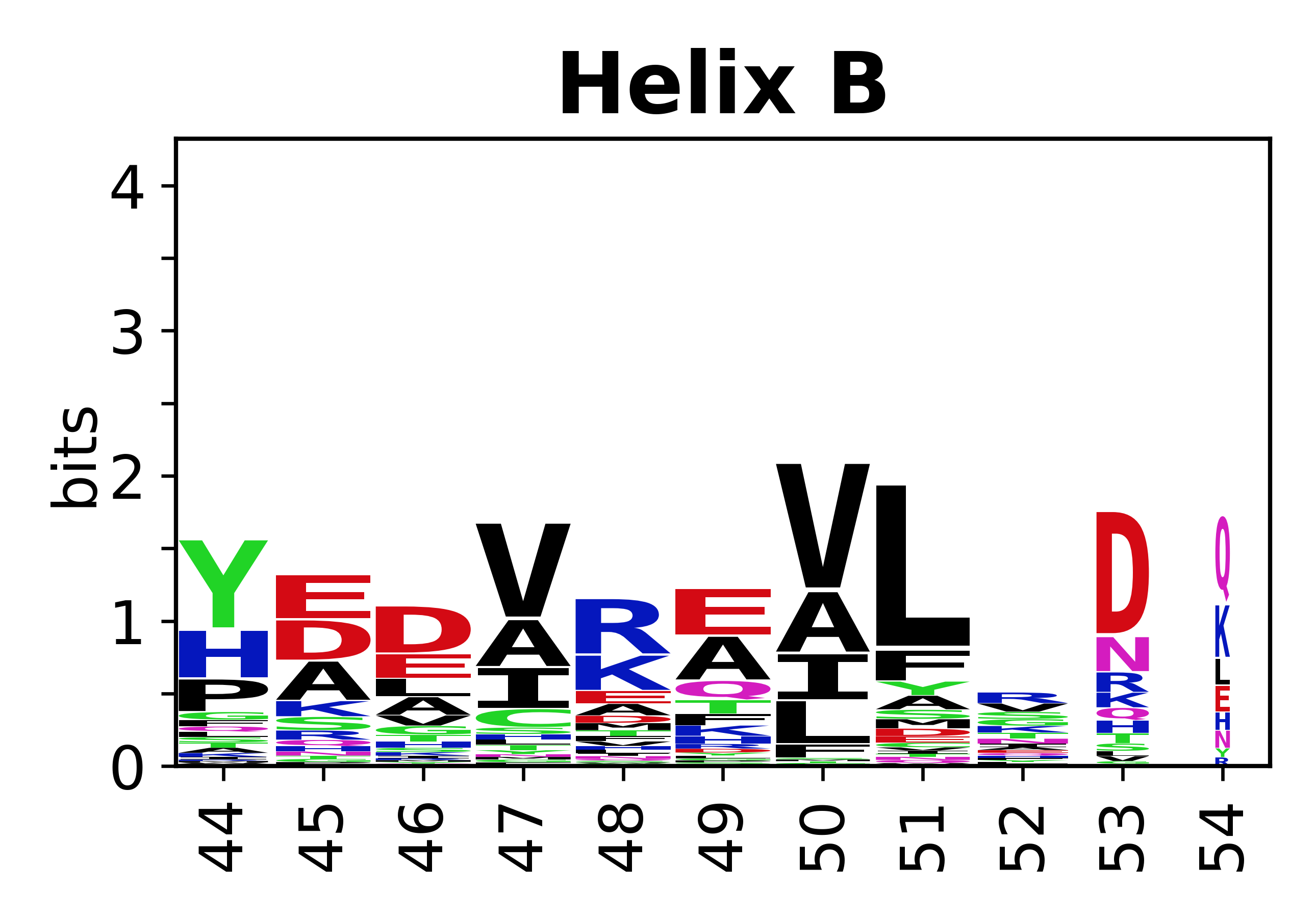
-
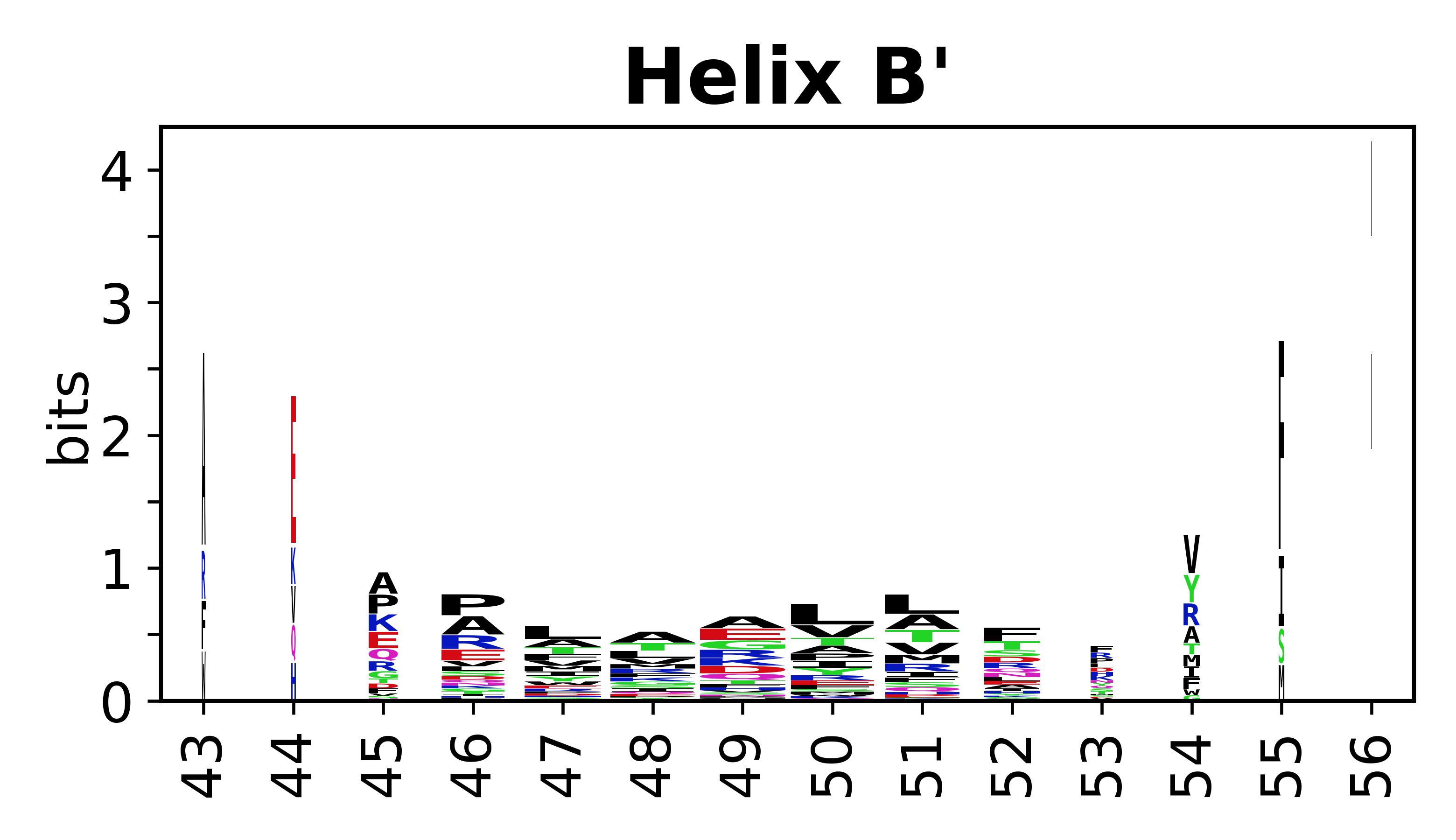
-
-
-
-
-
-
-
-
-
-

-
-
-
-
-
-

-
- Beta strands
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-